| CPC G10L 17/04 (2013.01) [G06F 21/32 (2013.01); G06N 20/20 (2019.01); G10L 17/18 (2013.01); G10L 17/26 (2013.01); G10L 21/0208 (2013.01)] | 18 Claims |
|
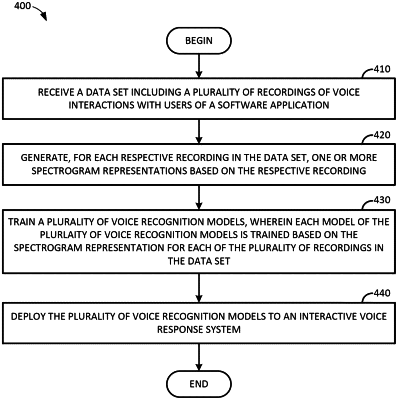
1. A method for training a user detection model to identify a user of a software application based on voice recognition, comprising:
receiving a data set including a plurality of recordings of voice interactions with users of a software application;
generating, for each respective recording in the data set, a spectrogram representation based on the respective recording, wherein the spectrogram representation is normalized with respect to a minimum amplitude and a maximum amplitude;
training a plurality of voice recognition models, wherein each model of the plurality of voice recognition models is trained based on the spectrogram representation for each of the plurality of recordings in the data set;
selecting, for a selected speaker of a plurality of speakers, an evaluation set of recordings;
identifying a similar speaker to the selected speaker by:
providing inputs based on the evaluation set of recordings to one or more of the plurality of voice recognition models, and
receiving an output from the one or more of the plurality of voice recognition models identifying the similar speaker as the selected speaker;
re-training the one or more of the plurality of voice recognition models based on a mapping of the selected speaker to the identified similar speaker; and
deploying the plurality of voice recognition models to an interactive voice response system.
|