| CPC G10L 15/30 (2013.01) [G06F 3/167 (2013.01); G10L 15/1822 (2013.01); G10L 25/72 (2013.01); G10L 2015/223 (2013.01); G10L 2015/225 (2013.01)] | 15 Claims |
|
1. A method implemented by one or more processors comprising:
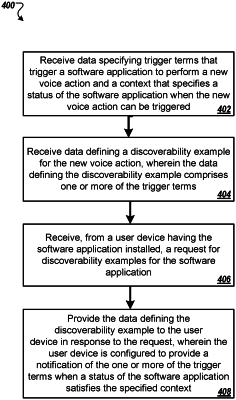
receiving, from a third party application developer, data defining a new voice action for a software application, wherein the data defining the new voice action comprises a trigger term or phrase that triggers the software application to perform the new voice action, a predetermined amount of time associated with performing the new voice action, and a context that specifies a user device status and a software application status when the new voice action can be triggered;
receiving, from the third party application developer, data defining a discoverability example for the new voice action, wherein the data defining the discoverability example comprises a notification including at least the trigger term or phrase, for the new voice action, to inform users how to trigger the new voice action;
subsequent to receiving, from the third party application developer, the data defining the new voice action for the software application, and the data defining the discoverability example for the new voice action:
receiving, from a user of a user device having the software application installed, a request for discoverability examples for a current context;
receiving, from the user device, the current context of the request, the current context of the request including a user device context and a software application context, wherein the user device context indicates that the software application is operating in a foreground of the user device when the request is received and further indicates whether the user device is in a particular device mode, and wherein the software application context indicates a particular mode that the software application is currently in when the request is received;
determining that the current context matches the context for the new voice action defined by the third party application developer, wherein determining that the current context matches the context for the new voice action defined by the third party developer comprises:
determining that the user device context matches the user device status for the new voice action defined by the third party application developer, and
determining that the software application context matches the software application status for the new voice action defined by the third party application developer; and
in response to receiving the request for discoverability examples for the software application from the user, determining the user device context matches the user device status for the new voice action defined by the third party application developer, and determining the software application context matches the software application status for the new voice action defined by the third party application developer:
identifying the data defining the discoverability example for the new voice action; and
causing the user device to output, for presentation to the user of the user device, the notification in a particular type that is selected, based on the current context, from a group that includes a textual format, an image format, a video format, and an audio format, the notification including at least the trigger term or phrase, for the new voice action, to inform the user how to trigger the new voice action.
|