| CPC G08B 6/00 (2013.01) [G06N 3/0455 (2023.01); G06N 3/084 (2013.01); G06N 3/0895 (2023.01); G06V 10/806 (2022.01); G06V 20/46 (2022.01)] | 5 Claims |
|
1. An audio-visual-aided haptic signal reconstruction method based on a cloud-edge collaboration, wherein the method comprises following steps:
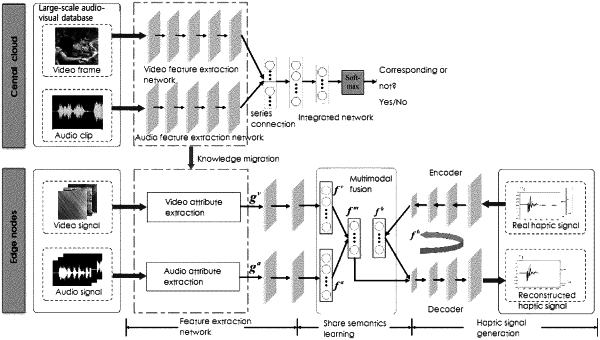
Step (1), executing, on a large-scale audio-visual database stored on a central cloud, a self-supervision learning task, wherein the self-supervision learning task refers to determining whether video frames and audio clips are from a same audio-visual source, thereby obtaining a pre-trained audio feature extraction network and a pre-trained video feature extraction network;
Step (2), designing, at an edge node, an audio-visual-aided haptic signal reconstruction AVHR model, the reconstruction AVHR model being specifically as follows:
first taking, after receiving audio signals and video signals by the edge node, the pre-trained audio feature extraction network and the pre-trained video feature extraction network on the central cloud as an audio attribute extraction network and a video attribute extraction network of the edge node, further extracting, after extracting audio signal attributes and video signal attributes, audio signal features and video signal features associated between the audio signals and the video signals from the audio signal attributes and the video signal attributes;
then, fusing, by using a fusion network combining a multi-modal collaboration and a multi-modal joint paradigm, the audio signal features and the video signal features, and obtaining fused features;
simultaneously, extracting, by a haptic feature extraction network, haptic signal features;
training, according to the audio signal features, the video signal features, the haptic signal features and the fused features, an audio feature extraction network, a video feature extraction network, the haptic feature extraction network and the fusion network, by using a semantic correlation learning and semantic discrimination learning strategies, and learning shared semantics of the audio signals, the video signals, the haptic signals and the fused features, to obtain the fused features containing the shared semantics; and
inputting the fused features containing the shared semantics into a haptic signal generation network with semantic constraints, to implement a reconstruction of a target haptic signal;
Step (3), training, by a gradient descent algorithm, the AVHR model at the central cloud and the edge node respectively, to obtain structures and parameters for an optimal AVHR model; and
Step (4), inputting paired audio signals and video signals to be tested into the optimal AVHR model, wherein the optimal AVHR model is configured to extract and fuse semantic features of the audio signals and the video signals, and generate the target haptic signal by fused semantic features.
|