| CPC G06N 3/084 (2013.01) [G06F 40/47 (2020.01); G06F 40/58 (2020.01)] | 20 Claims |
|
12. A system for sequence-to-sequence prediction comprising:
a memory storing a plurality of processor-executable instructions; and
a processor reading and executing the processor-executable instructions from the memory to perform operations comprising:
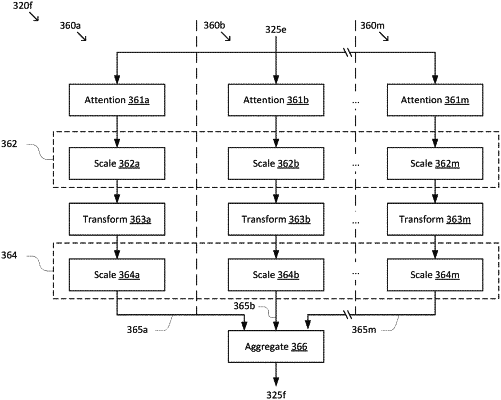
an encoder stage that generates, by an encoder, an encoded representation based on an input sequence, wherein the encoder includes a set of branched attention layers arranged sequentially, each branched attention layer includes a plurality of branches arranged in parallel, and each branch includes a respective attention sublayer and a respective scaling sublayer, wherein the generating includes generating, at each branched attention encoder layer of the set of branched attention encoder layers, a respective layer encoded representation for a corresponding branched attention decoder layer in a decoder by:
determining, at the respective attention sublayer of a respective branch, a respective learned scaling parameter depending on one or more other learned scaling parameters from one or more other branches;
applying, at the respective scaling sublayer of the respective branch, a respective attention to the input sequence in parallel to other branches, based on scaling a respective intermediate representation of the respective branch by the respective learned scaling parameter;
an aggregation node that aggregates a plurality of branch output representations generated by each of the plurality of branches to generate the respective layer encoded representation; and
a decoder stage that predicts, by a decoder comprising a set of branched attention decoder layers, an output sequence based on a set of respective layer encoded representations sequentially received from the set of branched attention encoder layers.
|