| CPC G06F 40/284 (2020.01) [G06F 40/30 (2020.01); G06N 5/04 (2013.01); G06N 20/00 (2019.01); G06V 10/811 (2022.01); G06V 20/30 (2022.01)] | 11 Claims |
|
1. A multi-modal pre-training model acquisition method, comprising:
determining, for each image-text pair as training data, to-be-processed fine-grained semantic words in the text;
masking the to-be-processed fine-grained semantic words; and
training the multi-modal pre-training model using the training data with the fine-grained semantic words masked,
wherein determining the to-be-processed fine-grained semantic words in the text comprises:
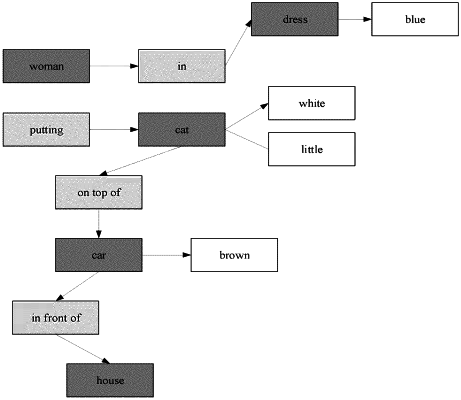
acquiring a scene graph corresponding to the text, wherein the scene graph comprises: entity nodes, attribute tuples and relationship triples, each attribute tuple is composed of one entity node and one attribute node, and each relationship triple is composed of two entity nodes and one relationship node;
selecting a predetermined number of entity nodes, attribute tuples and relationship triples from the scene graph, and taking entity words in the text corresponding to the selected entity nodes, attribute words in the text corresponding to attribute nodes in the selected attribute tuples, and relationship words in the text corresponding to relationship nodes in the selected relationship triples, as the to-be-processed fine-grained semantic words.
|