| CPC G06F 16/93 (2019.01) [G06F 16/958 (2019.01)] | 9 Claims |
|
1. A method for loading a PDF document in a webpage, comprising:
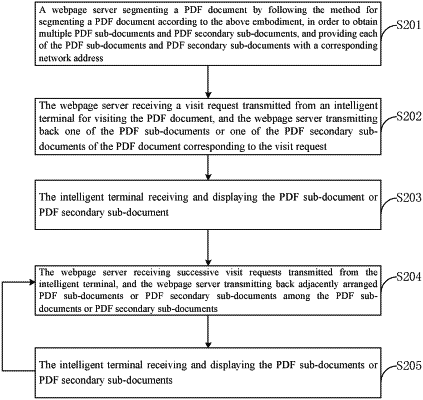
a webpage server segmenting a PDF document by using a method for segmenting a PDF document, in order to obtain multiple PDF sub-documents and PDF secondary sub-documents, and providing each of the PDF sub-documents and PDF secondary sub-documents with a corresponding network address;
the webpage server receiving a visit request transmitted from an intelligent terminal for visiting the PDF document, and the webpage server transmitting back one of the PDF sub-documents or one of the PDF secondary sub-documents of the PDF document corresponding to the visit request;
the intelligent terminal receiving and displaying the PDF sub-document or PDF secondary sub-document;
the webpage server receiving successive visit, requests transmitted from the intelligent terminal, and the webpage server transmitting back adjacently arranged PDF sub-documents or PDF secondary sub-documents among the PDF sub-documents or PDF secondary sub-documents;
the intelligent terminal receiving and displaying the PDF sub-documents or PDF secondary sub-documents; and
repeatedly executing the steps of the webpage server receiving successive visit requests transmitted from the intelligent terminal the webpage server transmitting back adjacently arranged PDF sub-documents or PDF secondary sub-documents among the PDF sub-documents or PDF secondary sub-documents and the intelligent terminal receiving and displaying the PDF sub-documents or PDF secondary sub-documents to realize continuous displaying of the PDF sub-documents and the PDF secondary sub-documents of the PDF document,
wherein the method for segmenting a PDF document comprises:
inspecting whether the PDF document includes an original directory structure or not;
if the PDF document includes an original directory structure, segmenting the PDF document into multiple PDF sub-documents according to the original directory structure; and
if the PDF document does not include an original directory structure, segmenting the PDF document into multiple PDF sub-documents according to document contents of the PDF document and a lexical database corresponding to the PDF document.
|