| CPC G06F 16/243 (2019.01) [G06F 16/221 (2019.01); G06F 16/24578 (2019.01); G06F 16/2458 (2019.01); G06F 16/248 (2019.01)] | 19 Claims |
|
1. A method comprising:
collecting, by a computing device, samples from a plurality of columns of a dataset;
encoding, by the computing device, the samples using a semi-supervised algorithm, thereby creating sample embeddings;
creating, by the computing device, a plurality of column embeddings using the sample embeddings;
storing, by the computing device, the plurality of column embeddings in a content store;
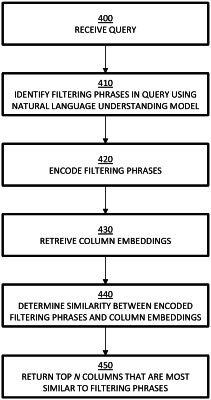
receiving, by the computing device, a natural language search query;
determining, by the computing device, a filtering phrase in the natural language search query using a natural language understanding model;
encoding, by the computing device, the filtering phrase using the same semi- supervised algorithm used to encode the samples;
retrieving, by the computing device, the plurality of column embeddings from the content store and loading the retrieved plurality of column embeddings into memory;
for each of the plurality of column embeddings, the computing device determining a similarity score based on a similarity between the encoded filtering phrase and the column embedding; and
outputting, by the computing device, a column of the plurality of columns of the dataset that is most similar to the filtering phrase in the natural language query based on the column corresponding to column embedding of the plurality of column embeddings having a highest similarity score.
|