| CPC H04N 21/8153 (2013.01) [G06V 10/761 (2022.01); H04N 5/2628 (2013.01); H04N 19/46 (2014.11); H04N 21/812 (2013.01)] | 20 Claims |
|
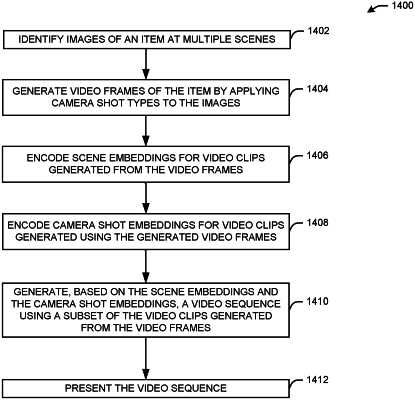
1. A method for generating video clips of a product based on still frame images of the product, the method comprising:
identifying, by at least one processor of a device associated with an online retail system, a first image representing a product at a first scene, the product for sale using the online retail system;
identifying, by the at least one processor, a second image representing the product at a second scene different than the first scene;
generating, by the at least one processor, based on the first image, first images representing the product at the first scene and using a first type of camera shot;
generating, by the at least one processor, based on the second image, second images representing the product at the second scene and using a second type of camera shot different than the first type of camera shot;
encoding, by the at least one processor, using a first encoder network, first embeddings for a first video comprising the first images, the first embeddings indicative of features of the first scene;
encoding, by the at least one processor, using the first encoder network, second embeddings for a second video, the second embeddings indicative of features of the second scene;
encoding, by the at least one processor, using a second encoder network, third embeddings for the first video, the third embeddings indicative of camera shot features of the first video;
encoding, by the at least one processor, using the second encoder network, fourth embeddings for the second video, the fourth embeddings indicative of camera shot features of the second video; and
generating, by the at least one processor, using machine learning models, based on the first embeddings, the second embeddings, the third embeddings, and the fourth embeddings, a video sequence for the product, the video sequence comprising one of the first video or the second video.
|