| CPC H04L 65/4015 (2013.01) [G10L 15/1815 (2013.01); H04L 65/1093 (2013.01); H04L 65/611 (2022.05)] | 20 Claims |
|
1. A first computer system comprising at least one data store and at least one computer processor,
wherein the first computer system is connected to one or more networks,
wherein the at least one data store has one or more sets of instructions stored thereon that, when executed by the at least one computer processor, cause the first computer system to perform a method comprising:
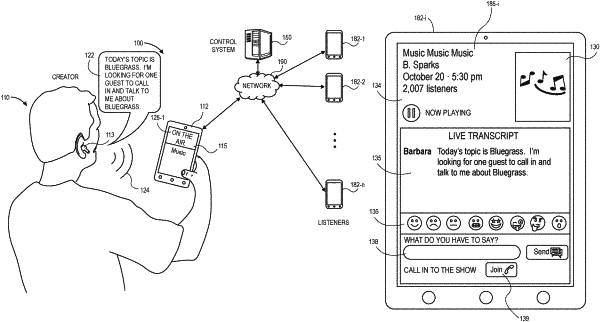
receiving a first set of audio data from a second computer system over the one or more networks, wherein the second computer system is associated with a creator of a media program, and wherein the first set of audio data represents one or more sets of words spoken by the creator and captured by the second computer system;
transmitting at least a portion of the first set of audio data to a plurality of computer systems over the one or more networks in accordance with an episode of the media program, wherein each of the plurality of computer systems is associated with at least one listener to the episode of the media program;
receiving sets of audio data from a subset of the plurality of computer systems over the one or more networks, wherein each of the sets of audio data is received from one of the subset of the plurality of computer systems, and wherein each of the sets of audio data represents a set of words spoken by a listener to the media program and captured by one of the computer systems of the subset;
determining at least one attribute of each of the sets of audio data received from the subset of the plurality of computer systems;
identifying a set of words represented in each of the sets of audio data received from the subset of the plurality of computer systems;
determining at least one sentiment of each of the sets of audio data received from the subset of the plurality of computer systems, wherein the at least one sentiment is determined according to one or more machine learning algorithms based at least in part on the at least one attribute of one of the sets of audio data received from the subset of the plurality of computer systems and the set of words represented in the one of the sets received from the subset of the plurality of computer systems;
selecting one of the plurality of listeners based at least in part on:
at least one attribute of a second set of audio data received from one of the plurality of computer systems associated with the selected one of the plurality of listeners;
a set of words represented in the second set of audio data; and
a sentiment of the second set of audio data;
receiving a third set of audio data from a third computer system over the one or more networks, wherein the third computer system is associated with the selected one of the plurality of listeners, and wherein the third set of audio data represents one or more sets of words spoken by the selected one of the plurality of listeners and captured by the third computer system; and
transmitting at least a portion of the third set of audio data to the plurality of computer systems over the one or more networks in accordance with the episode of the media program.
|