| CPC G10L 21/0232 (2013.01) [G10L 17/02 (2013.01); G10L 25/21 (2013.01); G10L 25/24 (2013.01); G10L 25/84 (2013.01); H04L 65/1076 (2013.01); H04L 67/306 (2013.01); G16Y 40/10 (2020.01)] | 20 Claims |
|
1. A computer-implemented method for modifying audio-based communications produced during a conference call, comprising:
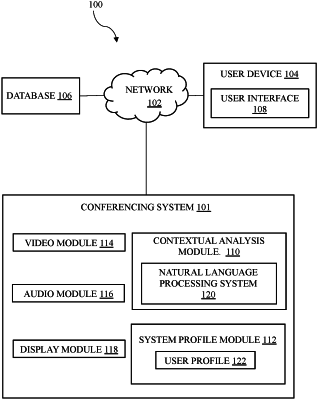
monitoring a plurality of utterances transmitted via an audio feed of a device connected to the conference call associated with one or more users;
monitoring a plurality of images from a video feed associated with the device connected to the conference call associated with one or more users the one or more users;
analyzing at least one user profile associated with the one or more users, wherein the user profile includes historical contextual activity;
extracting a particular contextual situation from the historical contextual activity, wherein (i) the particular contextual situation is determined, based in part, on the plurality of utterances transmitted via the audio feed and the plurality of images from transmitted via the video feed and (ii) the particular contextual situation for the video feed is extracted via a Regional-Based Convolutional Neural Network (R-CNN) enabled camera;
identifying a first unwanted audio component transmitted via the audio feed from the historical contextual activity;
actively modifying the audio feed by removing the first unwanted audio component from the audio feed;
identifying a first unwanted video component transmitted via the video feed from the historical contextual activity; and
actively modifying the video feed associated with the first unwanted video component, wherein the first unwanted video component is eliminated or obscured in the video feed.
|