| CPC G10L 17/00 (2013.01) [G06F 3/167 (2013.01); G10L 15/22 (2013.01); G10L 2015/223 (2013.01)] | 20 Claims |
|
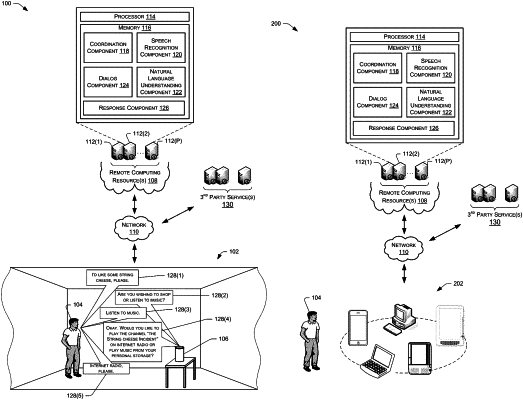
1. A system comprising:
one or more processors; and
non-transitory computer-readable media storing computer-executable instructions that, when executed by the one or more processors, cause the one or more processors to perform operations comprising:
receiving first audio data representing speech input;
generating speech-recognition data based at least in part on the first audio data;
receiving first data indicating a context associated with the first audio data, the context including an indication of content being displayed on a display of a device while the first audio data is received; and
generating, based at least in part on the speech-recognition data and the first data, second audio data to be output by the device, the second audio data representing a response to the speech input.
|