| CPC G10L 15/183 (2013.01) [G06F 16/3329 (2019.01); G06F 16/3337 (2019.01); G06F 18/22 (2023.01); G06F 40/47 (2020.01); G06F 40/58 (2020.01); G06N 20/00 (2019.01); G10L 15/005 (2013.01); G10L 15/22 (2013.01); H04L 51/02 (2013.01)] | 17 Claims |
|
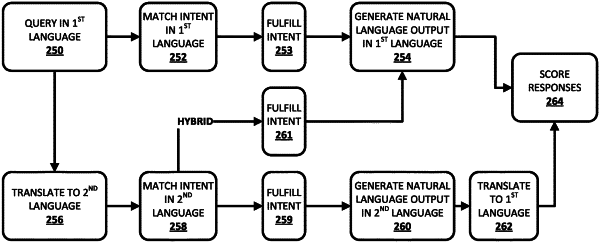
1. A method implemented by one or more processors, comprising:
receiving voice input provided by a user at an input component of a client device in a first language;
generating speech recognition output from the voice input, wherein the speech recognition output is in the first language;
identifying, as a slot value in the speech recognition output, a named entity in the first language;
translating at least a portion of the speech recognition output from the first language to a second language to generate an at least partial translation of the speech recognition output, wherein the translating includes preserving the named entity as the slot value in the first language, and wherein the translating is based on a machine learning model that is trained using one or more logs of user queries submitted to one or more automated assistants during human-to-computer dialogs;
identifying a second language intent of the user based on the at least partial translation and the preserved slot value;
fulfilling the second language intent to generate fulfillment information;
based on the fulfillment information, generating a natural language output candidate in the first or second language; and
causing the client device to present the natural language output at an output component of the client device.
|