| CPC G10L 15/18 (2013.01) [G10L 15/22 (2013.01); G10L 19/008 (2013.01); H04R 3/005 (2013.01); G10L 13/027 (2013.01); G10L 2015/225 (2013.01)] | 20 Claims |
|
1. A computer-implemented method comprising:
receiving, from a microphone array comprising a plurality of microphones, audio data representing an utterance, wherein the audio data comprises:
a first audio signal representing audio captured by a first microphone of the microphone array, and
a second audio signal representing audio captured by a second microphone of the microphone array;
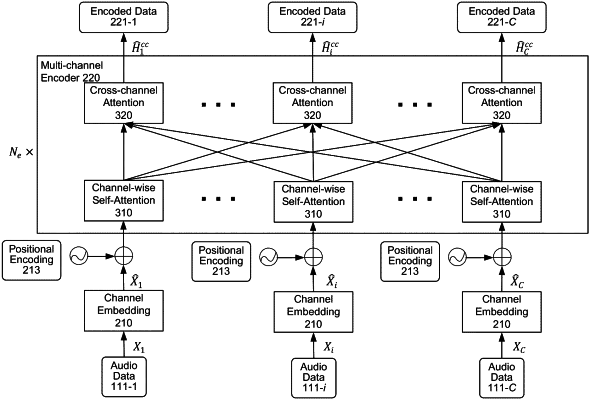
processing the first audio signal to determine first embedded audio data;
processing the second audio signal to determine second embedded audio data;
processing the first embedded audio data using a self-attention component to determine first attended data representing a correlation between first time frames within the first embedded audio data;
processing the second embedded audio data using the self-attention component to determine second attended data representing correlation between second time frames within the second embedded audio data;
processing at least the first attended data and the second attended data using a cross-channel attention component to determine third attended data corresponding to the first audio signal, the third attended data representing correlation between the first audio signal and at least one other audio signal of the audio data;
processing at least the first attended data and the second attended data using the cross-channel attention component to determine fourth attended data corresponding to the second audio signal, the fourth attended data representing correlation between the second audio signal and at least one other audio signal of the audio data; and
processing the third attended data and the fourth attended data to determine output data representing at least one acoustic unit representing the utterance.
|