| CPC G10L 13/047 (2013.01) [G10L 13/08 (2013.01); G10L 25/30 (2013.01)] | 24 Claims |
|
1. A method implemented by one or more processors, the method comprising:
iteratively generating samples of an audio waveform that is synthesized speech of provided text, wherein generating the samples of the audio waveform comprises:
at each iteration of a plurality of sequential iterations:
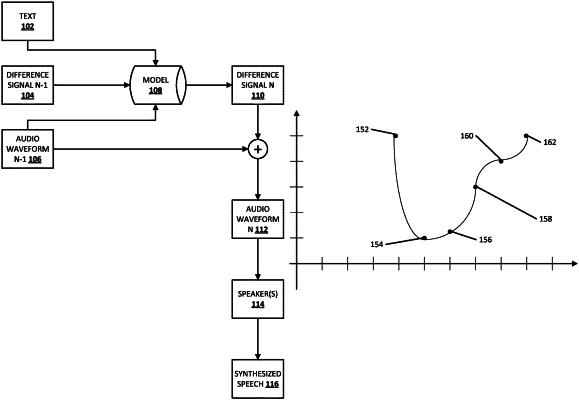
generating a respective difference signal for the iteration using an autoregressive model, wherein the respective difference signal is a predicted difference based on an amplitude of a respective preceding sample of the audio waveform generated in an immediately preceding iteration and an amplitude of a respective sample for the iteration, wherein an input to the autoregressive model comprises:
a respective representation of at least part of the provided text,
the respective preceding sample of the audio waveform generated in the immediately preceding iteration of the sequential iterations, and
a respective preceding difference signal generated in the immediately preceding iteration; and
determining the respective sample for the iteration using the respective difference signal for the iteration and the respective preceding sample of the audio waveform generated in the immediately preceding iteration, the respective sample for the iteration being one of the samples of the audio waveform; and
causing a client device to render the audio waveform by rendering the samples of the audio waveform.
|