| CPC G06V 40/23 (2022.01) [B25J 9/163 (2013.01); B25J 9/1697 (2013.01); G05B 13/0265 (2013.01); G06V 10/40 (2022.01); G06V 20/10 (2022.01); G06V 40/103 (2022.01)] | 20 Claims |
|
1. A computer-implemented method comprising:
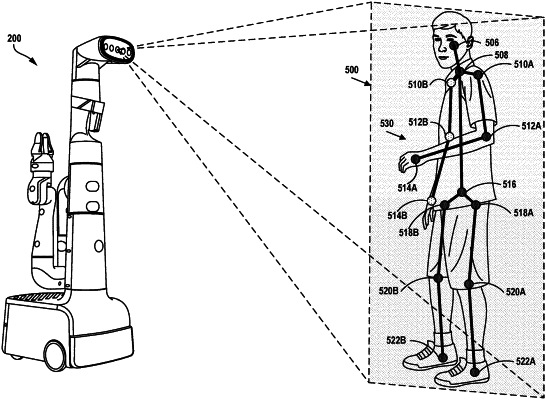
receiving, from a camera disposed on a robotic device, an image representing at least part of a body of an actor;
determining, for each respective keypoint of a first keypoint subset of a plurality of keypoints, coordinates of the respective keypoint within the second image, wherein the plurality of keypoints represent a corresponding plurality of predetermined body locations, and wherein each respective keypoint of the first keypoint subset is visible in the image;
determining a second keypoint subset of the plurality of keypoints, wherein each respective keypoint of the second keypoint subset is not visible in the image; and
determining, by way of a machine learning model, an extent of engagement of the actor with the robotic device, wherein the machine learning model is configured to determine the extent of engagement based on (i) the coordinates of each respective keypoint of the first keypoint subset and (ii) for each respective keypoint of the second keypoint subset, an indication that the respective keypoint is not visible in the image, wherein the machine learning model has been trained using a plurality of training images of a plurality of actors, wherein each respective training image of the plurality of training images is associated with a label indicating a corresponding extent of engagement, wherein each respective image has been captured by the camera or a second camera disposed on a second robotic device, and wherein the second camera approximates a perspective of the camera by being positioned on the second robotic device within a threshold height relative to a height of the camera on the robotic device.
|