| CPC G06N 3/084 (2013.01) [G06N 5/046 (2013.01)] | 22 Claims |
|
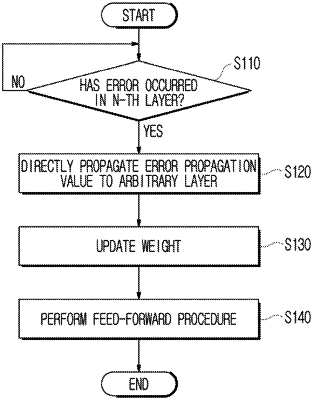
1. An apparatus for training a deep neural network including N layers, each having multiple neurons, the apparatus comprising:
an error propagation processing unit configured to, when an error occurs in an N-th layer in response to initiation of training of the deep neural network, determine an error propagation value for an arbitrary layer based on the error occurring in the N-th layer and then directly propagate the error propagation value to the arbitrary layer;
a weight gradient update processing unit configured to update a forward weight (W) for the arbitrary layer based on both a feed-forward value input to the arbitrary layer and the error propagation value in response to transfer of the error propagation value; and
a feed-forward processing unit configured to, when update of the forward weight (W) is completed, perform a feed-forward operation in the arbitrary layer using the forward weight (W),
wherein the apparatus is configured such that:
each of the error propagation processing unit, the weight gradient update processing unit, and the feed-forward processing unit is implemented in a heterogeneous core architecture to be independently operable and controllable, and configured in a pipelined structure, and
each of the error propagation processing unit, the weight gradient update processing unit, and the feed-forward processing unit is configured to overlap each other within a predetermined processing time unit and operate in parallel,
wherein during the overlapping time, each of the error propagation processing unit, the weight gradient update processing unit, and the feed-forward processing unit is configured to operate in parallel with each other in different layers, in different neurons in the same layer, or in the same neuron.
|