| CPC G06F 21/6227 (2013.01) [G06F 21/602 (2013.01); H04L 9/008 (2013.01); H04L 9/0656 (2013.01); H04L 63/0428 (2013.01); H04L 63/1475 (2013.01)] | 21 Claims |
|
1. A computing system comprising:
a hardware-implemented processor that, when executing instructions stored in a memory, is configured to:
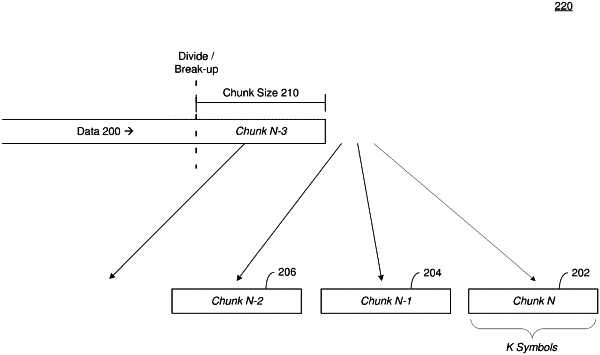
generate a first randomness value for a data chunk of a plurality of data chunks using a first randomness test, where the plurality of data chunks form a data file,
wherein when the first randomness value indicates that the data chunk is random, then the processor is further configured to:
increment a stored accumulated randomness value corresponding to the data chunk without additional randomness testing of the data chunk, and
wherein when the first randomness value does not indicate that the data chunk is random, then the processor is further configured to:
generate a second randomness value for the data chunk via a second randomness test that is different than the first randomness test,
wherein when the second randomness value indicates that the data chunk is random, then the processor is further configured to:
increment the stored accumulated randomness value corresponding to the data chunk without additional randomness testing of the data chunk,
aggregate accumulated randomness values for each data chunk of the plurality of data chunks to generate an aggregated randomness value, and
identify the data file as random or not random based on a comparison of the aggregated randomness value to a predetermined threshold value.
|