| CPC H04N 21/4725 (2013.01) [H04N 21/278 (2013.01); H04N 21/44204 (2013.01); H04N 21/44213 (2013.01); H04N 21/4884 (2013.01); H04N 21/845 (2013.01); H04N 21/8545 (2013.01)] | 20 Claims |
|
1. A system comprising:
at least one processor; and
at least one non-transitory computer-readable storage medium having computer-executable instructions stored thereon which, when executed on the at least one processor, cause the system to perform operations comprising:
storing a plurality of media files in a database, the plurality of media files including movies and television shows;
storing, in the database, a plurality of transcripts associated with the plurality of media files;
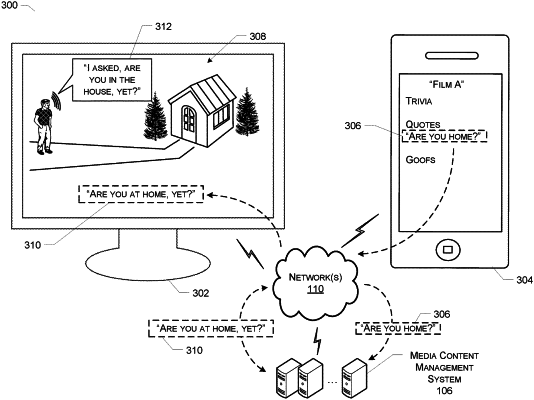
determining, from among the plurality of transcripts, a transcript associated with media content in a media file from among the plurality of media files;
extracting third-party information associated with a third-party web site;
determining a quote of a plurality of quotes in the third-party information associated with the media content;
determining first individual ones of a plurality of dialog segments associated with corresponding segments of the media content
determining second individual ones of a plurality of transcript segments of the transcript associated with the corresponding segments of the media content;
mapping, via a machine learning (ML) model, a quote to a media content segment of the media content that corresponds to one of the dialog segments matching the quote and one of the transcript segments matching the quote, a subtitle in the matching transcript segment having at least one first mappable element that is different from at least one corresponding mappable element of the quote, the at least one first mappable element including one or more of a first word, a first phrase, a first language, a first spelling, a first pronunciation, or a first punctuation, an audible utterance in the matching dialog segment having at least one second mappable element that is different from the at least one corresponding mappable element of the quote, the at least one second mappable element including one or more of a second word, a second phrase, a second language, a second spelling, a second pronunciation, or a second punctuation;
applying a smoothing algorithm to the media content segment to crop the media content segment;
receiving, based on input provided by a user via an external device, a request to display the media content segment; and
causing, based on the request, a video associated with the media content segment, to be output by the external device.
|