| CPC G10L 15/30 (2013.01) [G10L 15/22 (2013.01); G10L 13/033 (2013.01); G10L 13/08 (2013.01); G10L 2015/088 (2013.01); G10L 2015/223 (2013.01); G10L 2015/228 (2013.01); H04W 4/80 (2018.02)] | 20 Claims |
|
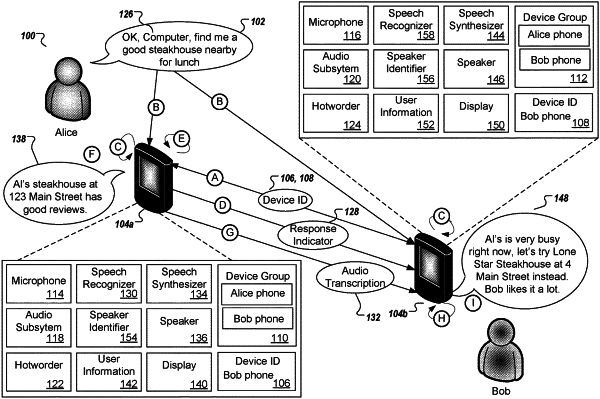
1. A method comprising:
determining, by a first computing device, that a second computing device is providing audible synthesized voice output in response to a prior utterance, spoken by a user, that was processed by the second computing device to generate the audible synthesized voice output; and
in response to determining that the second computing device is providing the audible synthesized voice output in response to the prior utterance spoken by the user:
generating, by the first computing device, additional synthesized voice output based on both:
the prior utterance spoken by the user, and
a transcription of the audible synthesized voice output provided in response to the prior utterance,
wherein content of the additional synthesized voice output varies from that of the audible synthesized voice output; and
providing, by the first computing device and for audible presentation, the additional synthesized voice output generated based on the prior utterance spoken by the user and the transcription of the audible user interface output provided in response to the prior utterance.
|