| CPC G10L 15/22 (2013.01) [G06F 16/635 (2019.01); G10L 15/05 (2013.01); G10L 2015/223 (2013.01)] | 12 Claims |
|
1. A speech control method, comprising:
acquiring target audio data sent by a client, the target audio data comprising audio data collected by the client within a target duration before wake-up and audio data collected by the client after wake-up;
performing speech recognition on the target audio data; and
controlling the client based on an instruction recognized from a second audio segment of the target audio data in response to recognizing a wake-up word from a first audio segment at beginning of the target audio data; in which, the second audio segment is later than the first audio segment or has an overlapping portion with the first audio segment, wherein a duration of the first audio segment is greater than the target duration;
wherein the method further comprises:
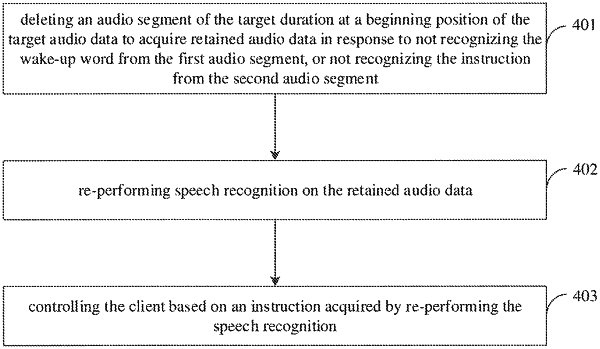
deleting an audio segment of the target duration at a beginning position of the target audio data to acquire retained audio data in response to not recognizing the wake-up word from the first audio segment, or not recognizing the instruction from the second audio segment;
re-performing speech recognition on the retained audio data to obtain a re-devised first audio segment and a re-devised second audio segment; and
controlling the client based on an instruction recognized from the re-divided second audio segment.
|