| CPC G06V 30/412 (2022.01) [G06F 16/35 (2019.01); G06F 18/214 (2023.01); G06V 30/413 (2022.01); G06V 30/414 (2022.01)] | 20 Claims |
|
1. A method for predicting field values of documents, the method comprising:
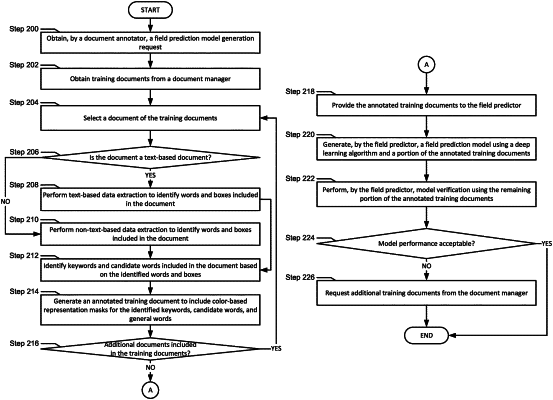
identifying, by a document annotator, a field prediction model generation request;
in response to identifying the field prediction model generation request:
obtaining, by the document annotator, training documents from a document manager;
selecting, by the document annotator, a first training document of the training documents;
making a first determination, by the document annotator, that the first training document is a text-based document; and
in response to the first determination:
performing, by the document annotator, text-based data extraction to identify first words and first boxes included in the first training document;
identifying, by the document annotator, first keywords and first candidate words included in the first training document based on the first words and first boxes, wherein the first keywords specify words associated with a field, and wherein the first candidate words specify potential field values of the field; and
generating, by the document annotator, a first annotated training document using the first keywords and the first candidate words, wherein the first annotated training document comprises color-based representation masks for the first keywords, the first candidate words, and first general words included in the first training document.
|