| CPC G06T 7/207 (2017.01) [G05D 1/0038 (2013.01); G05D 1/0238 (2013.01); G05D 1/0253 (2013.01); G06F 18/217 (2023.01); G06N 20/00 (2019.01); G06T 7/11 (2017.01); G06T 7/50 (2017.01); G06T 7/579 (2017.01); G06V 10/25 (2022.01); G06V 10/764 (2022.01); G06V 20/56 (2022.01); G06V 20/64 (2022.01); G06T 2207/20081 (2013.01); G06T 2207/20104 (2013.01); G06T 2207/30252 (2013.01)] | 17 Claims |
|
1. A system comprising:
one or more processors; and
a memory storing processor-executable instructions that, when executed by the one or more processors, cause the system to perform operations comprising:
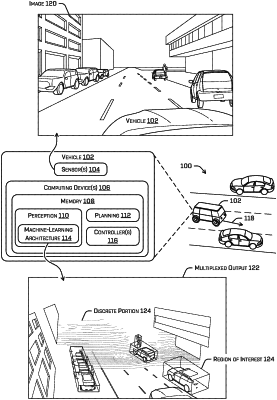
receiving an image from an image sensor associated with an autonomous vehicle;
inputting at least a portion of the image into a machine learned (ML) model;
determining, by the ML model and based on the image, a set of outputs, the set of outputs comprising:
a region of interest (ROI) associated with an object that appears in the image;
a semantic segmentation associated with the object, the semantic segmentation indicative of a classification of the object;
directional data that indicates a center of the object, wherein a portion of the directional data indicates a direction toward the center of the object from the portion;
depth data associated with at least the portion of the image, wherein determining the depth data comprises:
determining, a depth bin from among a set of depth bins, the depth bin associated with a discrete portion of an environment; and
determining a depth residual associated with the depth bin, the depth residual indicating a deviation of a surface associated with the discrete portion from a position associated with the depth bin; and
an instance segmentation associated with the object; and
controlling the autonomous vehicle based at least in part on at least one of the ROI, the semantic segmentation, the instance segmentation, or the depth data.
|