| CPC G06N 5/04 (2013.01) [G06F 16/93 (2019.01)] | 20 Claims |
|
1. A method comprising:
receiving documents from one or more databases, the documents including at least one of patents or patent applications;
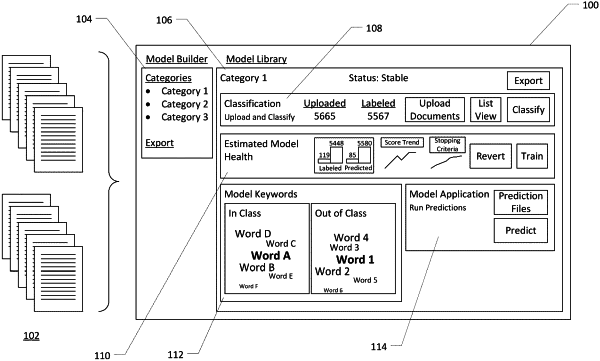
generating first data representing the documents and components of the documents, the components including at least a title portion, an abstract portion, and a claims portion;
generating a user interface configured to display:
the components of individual ones of the documents; and
an element configured to accept user input indicating whether the individual ones of the documents are in class or out of class;
generating a positive training dataset indicating positive vectors from a first portion of documents marked as in class in response to the user input;
generating a negative training dataset indicating negative vectors from a second portion of documents marked as out of class in response to the user input;
generating a machine learning classification model based at least in part on user input data corresponding to the user input, the machine learning classification model configured to determine whether a sample vector representing a document is closer to the positive vectors than the negative vectors in a coordinate system;
causing the user interface to display an indication of:
the first portion of the documents marked as in class in response to the user input;
the second portion of the documents marked as out of class in response to the user input;
a third portion of the documents determined to be in class utilizing the machine learning classification model; and
a fourth portion of the documents determined to be out of class utilizing the machine learning classification model.
|