| CPC G06N 3/08 (2013.01) [G06N 3/04 (2013.01); G06N 3/045 (2023.01); G06N 20/00 (2019.01)] | 20 Claims |
|
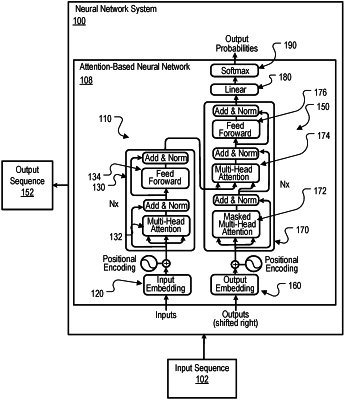
1. A system comprising one or more computers and one or more storage devices storing instructions that when executed by the one or more computers cause the one or more computers to implement a neural network for generating a network output by processing an input sequence having a respective network input at each of a plurality of input positions, the neural network comprising:
a first neural network comprising a sequence of one or more subnetworks, each subnetwork configured to (i) receive a respective subnetwork input for each of a plurality of preceding input positions that precede a current input position in an ordering of the input positions, and (ii) generate a respective subnetwork output for each preceding input position, and wherein each subnetwork comprises:
a self-attention sub-layer that is configured to receive the respective subnetwork input for each of the plurality of preceding input positions in the ordering of the input positions and, for each particular input position of the preceding input positions:
apply a self-attention mechanism over the subnetwork inputs at the preceding input positions to generate a respective output for the particular input position, wherein applying a self-attention mechanism comprises: determining a query according to the subnetwork input at the particular input position, determining keys derived from the subnetwork inputs at the preceding input positions, determining values derived from the subnetwork inputs at the preceding input positions, and using the determined query, keys, and values to generate the respective output for the particular input position.
|