| CPC G06F 9/5077 (2013.01) [G06F 9/45558 (2013.01); G06F 9/5027 (2013.01); G06N 3/02 (2013.01); G06F 2009/4557 (2013.01)] | 11 Claims |
|
1. A system for training parameters of a neural network using training data samples that include a plurality of input values and a target output value, comprising:
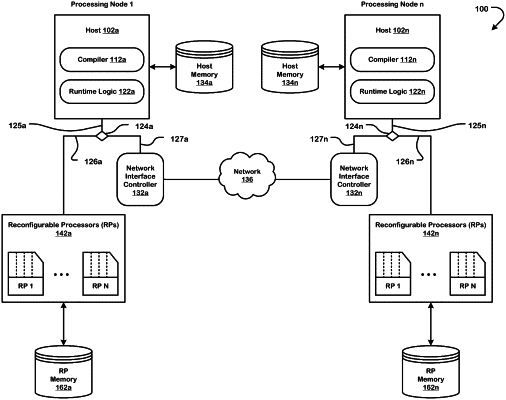
a plurality of processing nodes including a processing node and a second processing node, each processing node of the plurality of processing nodes includes:
a respective plurality of processors reconfigurable at a first level of configuration granularity;
a respective smart network interface controller comprising a respective controller configurable at a second level of configuration granularity; and
a respective interconnect fabric communicatively coupling processors of the respective plurality of processors to the respective smart network interface controller;
the processing node comprising a plurality of processors reconfigurable at the first level of configuration granularity, including a processor and a smart network interface controller comprising a controller reconfigurable at the second level of configuration granularity finer than the first level of configuration granularity, the controller communicatively coupled to the processor through an intra-node communication link, and to a network interface controller on the second processing node through a network;
the processor configured by a host system to execute a first dataflow segment of the neural network having one or more dataflow pipelines to generate a predicted output value using a first subset of the plurality of input values and a set of neural network parameters, calculate a first intermediate result for a parameter of the set of neural network parameters based on the predicted output value and the target output value, and provide the first intermediate result to the controller;
wherein the processor comprising a Coarse-Grained Reconfigurable Architecture (CGRA); and
the controller configured by the host system to receive a second intermediate result from the network interface controller though the network, execute a second dataflow segment, dependent upon the first intermediate result and the second intermediate result, to generate a third intermediate result indicative of an update of the parameter of the set of neural network parameters;
wherein the controller is configured to produce the third intermediate result using a collective methodology;
wherein the respective smart network interface controllers of the plurality of processing nodes are connected in a ring configuration and the collective methodology comprises a uni-directional ring all-reduce; and
wherein none of the first intermediate result, the second intermediate result, nor the third intermediate result, pass through the host system.
|