| CPC G06F 40/30 (2020.01) [G06F 40/117 (2020.01); G06F 40/232 (2020.01); G10L 25/30 (2013.01)] | 21 Claims |
|
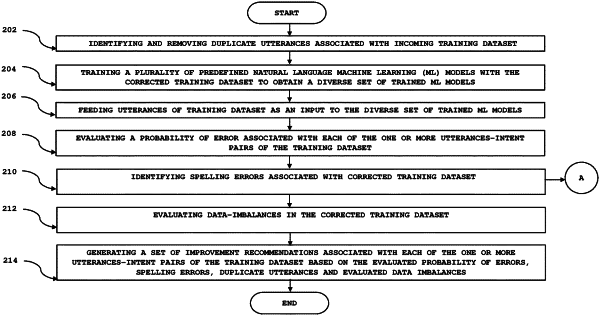
1. A method for improving a training dataset comprising one or more utterances-intent pairs, wherein the method is implemented by at least one processor executing program instructions stored in a memory, the method comprising:
training, by the at least one processor, a plurality of machine learning models with the training dataset to obtain a diverse set of trained Machine Learning (ML) models;
feeding, by the at least one processor, each utterance of the one or more utterances-intent pairs as an input to the diverse set of trained ML models to obtain respective intent predictions for each utterance;
evaluating, by the at least one processor, a probability of error associated with each utterances-intent pair of the training dataset based on an analysis of the respective intent predictions for each utterance, wherein:
a mismatch during mapping of the intent prediction for each utterance from each of the diverse set of ML models with the intent associated with the utterance in the training dataset and a similarity score associated with the intent predictions for each utterance less than or equal to a predefined similarity-threshold (ST) is indicative of a high probability of error, the similarity score (S) is representative of a percentage of ML models out of the diverse set of ML models providing similar intent predictions for same utterance,
a mismatch during the mapping and the similarity score (S) greater than or equal to the predefined similarity-threshold (ST) is indicative of a high probability of error,
a match during the mapping and the similarity score (S) less than or equal to the predefined similarity-threshold (ST) is indicative of a high probability of error, and
a match during the mapping and the similarity score (S) greater than or equal to the predefined similarity-threshold (ST) is indicative of a low probability of error; and
generating, by the at least one processor, a set of improvement recommendations associated with each utterances-intent pair of the training dataset based on the evaluated probability of error.
|