| CPC G06F 40/284 (2020.01) [G06F 40/205 (2020.01); G06F 40/237 (2020.01); G06F 40/30 (2020.01); G06F 40/42 (2020.01); G06V 30/194 (2022.01)] | 19 Claims |
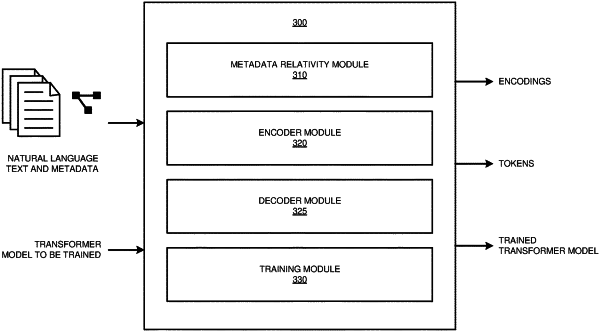
|
1. A computer-implemented method comprising:
constructing, from metadata of a corpus of natural language text documents, a relativity matrix, a row-column intersection in the relativity matrix corresponding to a relationship between two instances of turn-based metadata of a conversation; and
training an encoder model to compute an embedding corresponding to a token of a natural language text document within the corpus and the relativity matrix, the encoder model comprising a first encoder layer, the first encoder layer comprising a token embedding portion, a relativity embedding portion, a token self-attention portion, a metadata self-attention portion, and a fusion portion, the relativity embedding portion generating an input relativity embedding, the input relativity embedding encoding an entry in the relativity matrix, the metadata self-attention portion adjusting the input relativity embedding according to a set of metadata attention weights, the fusion portion combining an output of the token self-attention portion and an output of the metadata self-attention portion, the training comprising adjusting a set of parameters of the encoder model, the training generating a trained encoder model, wherein a parameter in the set of parameters of the encoder model is distinct from a layer in the encoder model,
wherein the training comprises a training stage in which (i) a parameter of the token embedding portion and (ii) a parameter of the token self-attention portion are each held constant,
and in which the training stage further changes (i) a parameter of the relativity embedding portion, and (ii) at least one parameter selected from a set of parameters comprising: the metadata self-attention portion, another attention portion, and the fusion portion.
|