| CPC G06F 21/32 (2013.01) [G06F 18/22 (2023.01); G06F 18/24137 (2023.01); G06F 21/46 (2013.01); G06N 5/04 (2013.01); G06N 20/00 (2019.01); G06Q 20/108 (2013.01); G06V 10/17 (2022.01); G06V 10/454 (2022.01); G06V 10/764 (2022.01); G06V 10/771 (2022.01); G06V 10/776 (2022.01); G06V 10/803 (2022.01); G06V 10/82 (2022.01); G06V 40/165 (2022.01); G06V 40/171 (2022.01); G06V 40/172 (2022.01); G06V 40/20 (2022.01); G06V 40/40 (2022.01); G10L 15/02 (2013.01); G10L 15/25 (2013.01); G06F 2221/2103 (2013.01); G10L 2015/025 (2013.01)] | 20 Claims |
|
1. A computer system for conducting a dynamic passphrase challenge to control access to a secure electronic resource, the computer system comprising a non-transitory computer readable storage device, computer memory, and a processor configured to:
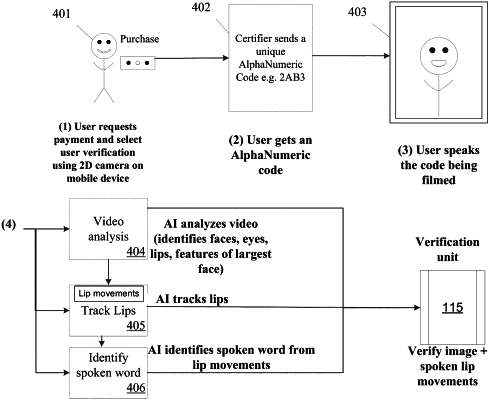
receive a script-reading video data set capturing a portion of or an entirety of an individual's face while the individual is speaking words corresponding to a script data structure, the script data structure having a sequence of pre-identified phonemes or phoneme transitions, the pre-identified phonemes or phoneme transitions including at least one overlapping phoneme or phoneme transition required to be spoken when speaking words of a correct response string;
extract, from the script-reading video data set, a data subset representing the one or more facial or lip features of the individual corresponding to each phoneme or phoneme transition corresponding to the sequence of pre-identified phonemes or phoneme transitions;
train, one or more baseline machine learning data model architectures, each baseline machine learning data model architecture of the one or more baseline machine learning data model architectures corresponding to a corresponding pre-identified phoneme or phoneme transition of the script data structure such that parameters of the baseline machine learning data model architectures are tuned based on the corresponding one or more facial or lip features;
receive an answer-reading video data set capturing a portion of or an entirety of the individual's face while the individual is speaking the words corresponding to the correct response string; and
process, the answer-reading video data set, using the one or more baseline machine learning data model architectures corresponding to the at least one overlapping phoneme or phoneme transition to determine an overall classification similarity score;
wherein a provisioning of access to the secure electronic resource only occurs if the overall classification similarity score is greater than a pre-defined threshold similarity score.
|