| CPC G06F 16/2365 (2019.01) [G06F 16/215 (2019.01); G06F 16/24556 (2019.01); G06F 16/254 (2019.01)] | 14 Claims |
|
1. A platform for automated data integration implemented on one or more hardware computer processors and one or more storage devices, the platform comprising:
an input database, wherein the input database is configured to upload data from a plurality of data sources comprising a plurality of data formats;
a data integration system, wherein the data integration system comprises a web application server, a data processing cluster, a metadata store and a message broker; and
an output database;
wherein the data integration system is configured to execute code in order to cause the system to:
receive inbound message by the message broker;
transmit data from the input database;
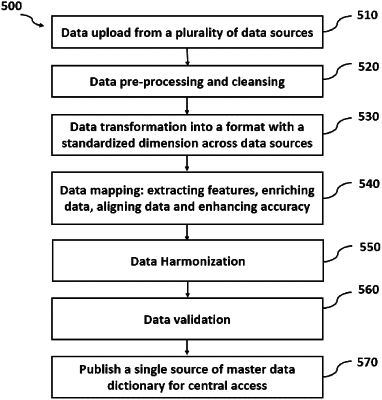
pre-process data including a plurality of records, wherein the pre-processing step comprises one or more of removing empty records, removing duplicate records, removing erroneous records, and filling missing records based on an average of historical data;
extract features from the pre-processed data by enabling a pattern recognition algorithm following a metadata-based mapping logic over the plurality of data types, wherein a metadata store is configured to store data type or feature definitions that are used to access data within the input database;
transform the plurality of data formats to a standardized data format that is selected by a user;
enrich the pre-processed data by enabling supervised learning to independently determine a decision boundary to separate different classes of the data by finding a linear or non-linear hyperplane or on a basis of conditional probabilities;
align the pre-processed data by enabling supervised learning by cleansing, distance matrix, and domain understanding to unify or de-duplicate records that have similar naming convention for a given feature and standardize text;
enhance accuracy of the pre-processed data through a user feedback loop by learning from previous prediction through the metadata-based mapping logic over the plurality of data types in the extract step and reducing errors in subsequent iterations of the user feedback loop;
harmonize previously unrelated structured and unstructured data stored in multiple separate databases;
generate master data of the harmonized previously unrelated structured and unstructured data of a plurality of business entities; and
publish the master data to the output database.
|