| CPC G06F 16/2255 (2019.01) [G06F 9/50 (2013.01); G06F 16/2379 (2019.01); G06F 16/245 (2019.01); G06F 11/34 (2013.01)] | 30 Claims |
|
1. A method, comprising:
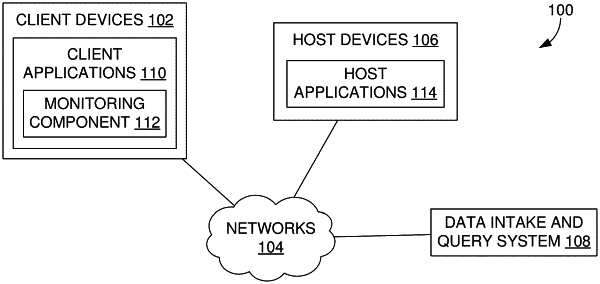
maintaining, by a data intake and query system, a resource catalog, the resource catalog identifying containerized indexing nodes instantiated in the data intake and query system, wherein each of the containerized indexing nodes are assignable to process data received by a partition manager of the data intake and query system and store results of processing the data in at least one bucket for execution of a query, wherein the resource catalog is maintained based on one or more communications by a component of the data intake and query system with each of the containerized indexing nodes;
receiving, from the partition manager, a request for a containerized indexing node that the partition manager can assign to process the data and store the results in the at least one bucket;
dynamically assigning a first containerized indexing node of the containerized indexing nodes to process the data and store the results in the at least one bucket, wherein the first containerized indexing node is dynamically assignable to process particular data and store corresponding results of processing the particular data based on determining that a second containerized indexing node assigned to process the particular data and store the corresponding results is unavailable;
determining the first containerized indexing node is available based on the resource catalog; and
communicating, to the partition manager, an indexing node identifier associated with the first containerized indexing node based on determining the first containerized indexing node is available, wherein the partition manager communicates the data to the first containerized indexing node based on the indexing node identifier, wherein the first containerized indexing node processes the data and stores the results in the at least one bucket.
|