| CPC G06F 16/213 (2019.01) [G06F 16/2465 (2019.01); G06F 16/258 (2019.01); G06F 16/285 (2019.01)] | 15 Claims |
|
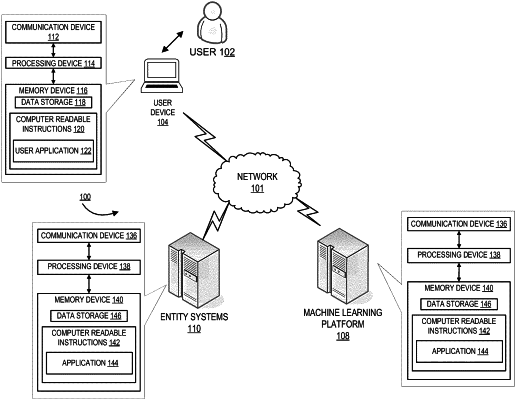
1. A system for organizing data objects, the system comprising:
a memory device with computer-readable program code stored thereon;
a communication device;
a processing device operatively coupled to the memory device and the communication device, wherein the processing device is configured to execute the computer-readable program code to:
receive entity data tables, wherein the entity data tables comprise data objects stored in a memory device of an entity system;
receive regulatory standard documentation comprising data handling guidelines identified from keywords in text of the regulatory standard documentation, wherein the regulatory standard documentation is a pdf file;
mine metadata from the entity data tables and mine the data handling guidelines from the regulatory standard documentation;
perform clustering on mined data using a K-means algorithm to determine a common grouping of the mined data to prepare for identification of a feature column group, wherein the mined data comprises the mined data handling guidelines and the mined metadata, and wherein the feature column group comprises one or more feature columns determined by the K-means algorithm to relate to other feature columns within the feature column group based on the metadata and data handling guidelines of the data objects within each of the feature columns;
import unknown data objects to a cell of a column;
identify the feature column of the column using a machine learning model trained using training data objects with known feature columns and known feature columns groups;
identify the feature column group based on data type and sensitivity; and
improve a confidence interval of the identified feature column of the feature column group by subjecting the data objects to the machine learning model multiple times.
|