| CPC G06F 16/1724 (2019.01) [G06F 3/0604 (2013.01); G06F 3/0643 (2013.01); G06F 3/0683 (2013.01); G06F 12/0253 (2013.01); G06F 16/182 (2019.01); G06F 16/908 (2019.01); G06F 16/9027 (2019.01)] | 16 Claims |
|
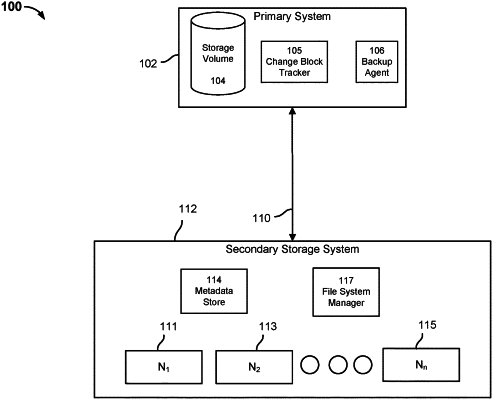
1. A method, comprising:
scanning, by a processor of a storage system, a plurality of tree data structures to determine a number of corresponding references associated with each data chunk included in a plurality of chunk files stored by the storage system and scanning the plurality of chunk files to determine a plurality of corresponding chunk file scores for each chunk file included in the plurality of chunk files stored by the storage system;
determining that a subset of the plurality of chunk files have corresponding chunk file scores above a chunk file score threshold, wherein determining the plurality of corresponding chunk file scores for the plurality of chunk files stored by the storage system includes assigning a worker of a plurality of workers to a corresponding tree data structure in the plurality of tree data structures stored by the storage system, wherein at least two workers of the plurality of workers each scan a different assigned tree data structure of the plurality of tree data structures in parallel;
including data chunks from the subset of the plurality of chunk files in a combined chunk file; and
deleting chunk files included in the subset of the plurality of chunk files from which the data chunks were included in the combined chunk file.
|