| CPC G06F 11/1451 (2013.01) [G06F 11/1469 (2013.01); G06F 16/219 (2019.01); G06F 16/2329 (2019.01); G06F 2201/80 (2013.01)] | 20 Claims |
|
1. A non-transitory computer readable storage medium having instructions stored thereon for performing data lineage based multi-data store recovery, the instructions, when executed by one or more hardware-implemented processors of a data recovery system, configured to direct the data recovery system to:
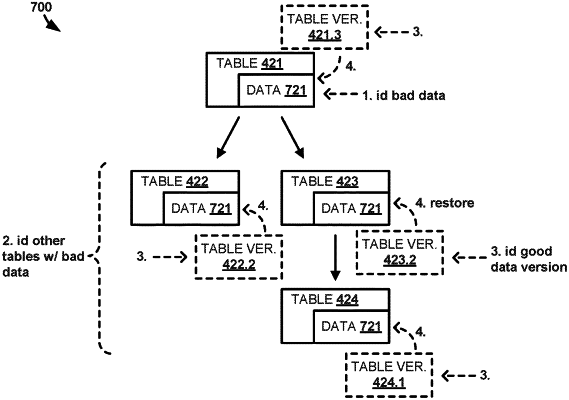
identify that a first version of a first table of a plurality of tables comprises a corrupt version of first data, the corrupt version of the first data comprising at least one corrupt data file and one or more correct versions of data files included in the first data;
identify a prior version of the first table that comprises a correct version of the first data, the correct version of the first data comprising a respective correct version of the at least one corrupt data file and the one or more correct versions of data files included in the first data;
restore the first data by replacing the at least one corrupt data file with the correct version of the at least one data file while maintaining the one or more correct versions of the data files included in the first data and using the correct version of the first data stored in the prior version of the first table;
identify, based at least in part on a review of data lineage for the plurality of tables, a set of second tables that descend from the first table and include respective sets of second data that stem from the first data including the at least one corrupt data file;
identify, for the set of second tables, respective prior versions of the set of second tables that comprise correct versions of the respective sets of second data based at least in part on the correct version of the first data, wherein the identified prior versions of at least two of the set of second tables are associated with different propagation times for the corrupt version of the first data; and
restore the respective sets of second data using the correct versions of the respective sets of second data stored in the identified prior versions of the set of second tables.
|