| CPC G01S 7/415 (2013.01) [G06N 20/00 (2019.01); G01S 7/417 (2013.01)] | 9 Claims |
|
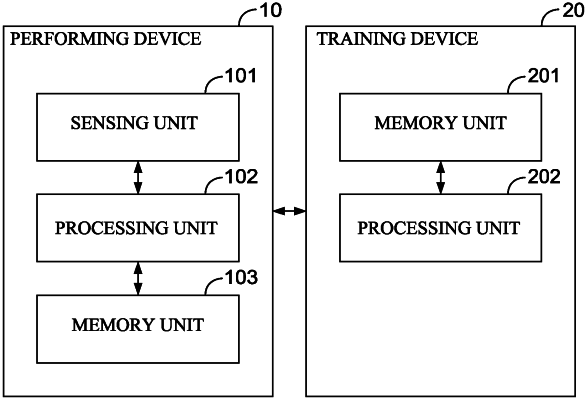
6. A gesture recognition system comprising:
a performing device; wherein the performing device comprises:
a Doppler radar, wherein the Doppler radar senses a sensing signal and the sensing signal comprises a plurality of sensing frames;
a first memory unit, wherein the first memory unit stores a deep learning-based model; and
a first processing unit electrically connected to the Doppler radar and the first memory unit, wherein the first processing unit receives the sensing signal from the Doppler radar, determines a prediction with at least one label according to the sensing frames by the deep learning-based model stored in the first memory unit, and classifies at least one gesture event according to the prediction;
wherein the at least one label labels at least one detection score of the deep learning-based model; and
a training device, wherein the training device comprises:
a second memory unit, wherein the second memory unit stores the deep learning-based model, a training signal, and a ground truth; wherein the training signal comprises a plurality of training frames; and
a second processing unit, electrically connected to the second memory unit of the training device; wherein the second processing unit receives the training signal, determines the prediction with the at least one label according to the training frames by the deep learning-based model, receives the ground truth with the at least one label, filters the prediction and the ground truth, measures the Manhattan distance between the filtered prediction and the filtered ground truth, and supervises a training of the deep learning-based model by using the Manhattan distance as a loss function;
wherein the deep learning-based model stored in the first memory unit is loaded from the second memory unit.
|