| CPC H04N 19/122 (2014.11) [H04N 19/124 (2014.11); H04N 19/159 (2014.11); H04N 19/176 (2014.11); H04N 19/18 (2014.11); H04N 19/82 (2014.11)] | 20 Claims |
|
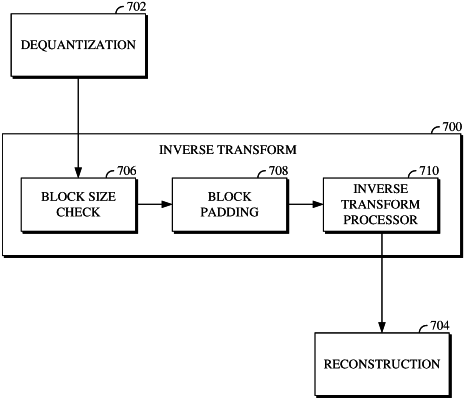
1. A method, comprising:
decoding an encoded video frame including:
determining whether a first transform size used to encode a first number of transform coefficients being decoded from a bitstream and associated with a first encoded block of the encoded video frame exceeds a threshold;
responsive to determining that the first transform size exceeds the threshold:
adding one or more coefficients to the first number of transform coefficients to result in a second number of transform coefficients; and
producing a first prediction residual block based on the second number of transform coefficients;
determining whether a second transform size used to encode a third number of transform coefficients being decoded from the bitstream and associated with a second encoded block of the encoded video frame exceeds the threshold; and
responsive to determining that the second transform size does not exceed the threshold, producing a second prediction residual block based on the third number of transform coefficients; and
outputting the decoded video frame, wherein the decoded video frame includes a first decoded video block produced based on the first prediction residual block and a second decoded video block produced based on the second prediction residual block.
|