| CPC H04L 27/0012 (2013.01) [G06N 3/084 (2013.01); H04B 7/0413 (2013.01)] | 6 Claims |
|
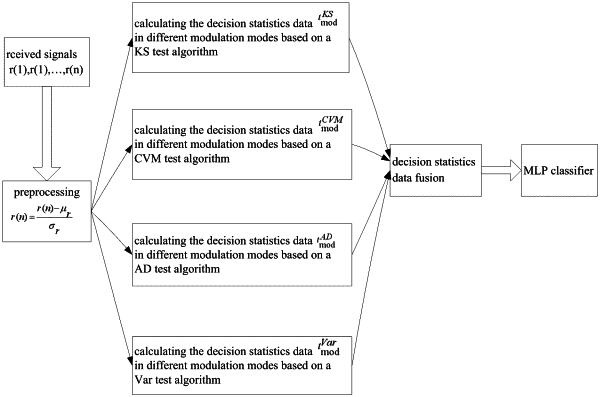
1. A fast modulation recognition method for a multilayer perceptron based on multimodally-distributed test data fusion, comprising the following steps:
step 1) preprocessing a received signal, a used normalization formula being:
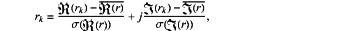 and
obtaining a signal feature sequence {zk}k =1N from the received signal {rk}k=1N, wherein
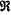 (rk) and (rk) and 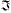 (rk) represent a real part and an imaginary part of the kth complex signal rk respectively, (r) and (r) represent a mean value of the real part and imaginary part of the complex signal respectively, and σ((r)) and σ((r)) represent a standard deviation of the real part and imaginary part of the complex signal respectively; (rk) represent a real part and an imaginary part of the kth complex signal rk respectively, (r) and (r) represent a mean value of the real part and imaginary part of the complex signal respectively, and σ((r)) and σ((r)) represent a standard deviation of the real part and imaginary part of the complex signal respectively;step 2) obtaining decision statistics data t*mod by using four distribution test algorithms: a Kolmogorov-Smirnov (KS) test, a Cramer-Von Mises test, an Anderson-Darling test, and a variance test, t*mod being defined as:
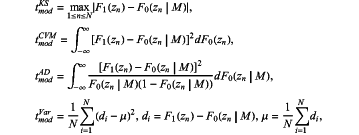 wherein F1(zn) is an empirical cumulative distribution of the received signal, F0(zn|M) is a theoretical cumulative distribution of a candidate modulation mode, Zn is a nth received signal, N is a number of feature values of the received signal organized in order, di, is a difference between the empirical cumulative distribution and the theoretical cumulative distribution, μ is a mean of the difference di, n is a total number of the candidate modulation mode, and M is the candidate modulation mode;
step 3) obtaining a matrix of t*mod:
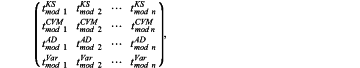 wherein tmod1ks is equivalent to
 when tested against a first of the candidate modulation mode M, tmod1CVM is equivalent to ∫−∞∞[F1(zn)−F0(zn|M)]2dF0(zn) when tested against a first of the candidate modulation mode M, tmod1AD is equivalent to
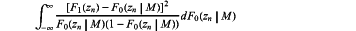 when tested against a first of the candidate modulation mode M, tmod1Var is equivalent to
 when tested against a first of the candidate modulation mode M, tmodnKS is equivalent to
 when tests against an nth of the candidate modulation mode M, tmodnCVM is equivalent to ∫−∞∞[F1(zn)−F0(zn|M)]2dF0(zn) when tested against an nth of the candidate modulation mode M, and tmodnAD is equivalent to
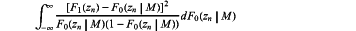 when tests against an nth of the candidate modulation mode M, and tmodnVar is equivalent to
 when tests against an nth of the candidate modulation mode M;
step 4) generating an input future of an MLP (multi-layer perception) classifier by using the matrix, the input future being defined as:
t*mod=tmod iKS+tmod iCVM+tmod iAD+tmod iVar, i=1,2, . . . ,n, wherein
an input feature of each modulation mode is inputted into the MLP classifier; and
stp 5) obtaining the input features of different modulation modes after the fusion of decision statistics data, recognizing the modulation modes by the MLP classifier with the input features, and matching an output with a corresponding classification label:
label={0,1,2, . . . ,n−1}
|