| CPC G10L 25/30 (2013.01) [G10L 21/0272 (2013.01); G10L 21/057 (2013.01)] | 20 Claims |
|
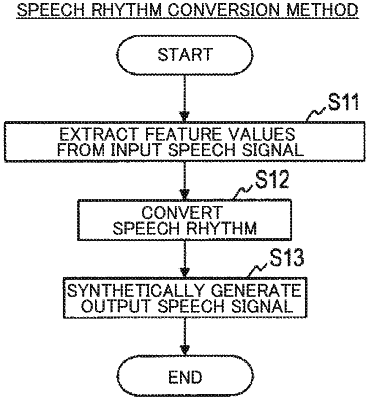
1. A speech rhythm conversion device comprising:
a model store configured to store a speech rhythm conversion model which is a neural network that:
receives, as an input thereto, a first feature value vector including first data associated with a speech rhythm of at least a phoneme extracted from a first speech signal resulting from a speech uttered by a speaker in a first group,
converts the speech rhythm of the first speech signal to a speech rhythm of a speaker in a second group, and
outputs the speech rhythm of the speaker in the second group;
a feature value extractor configured to extract, from an input speech signal resulting from the speech uttered by the speaker in the first group, second data associated with a vocal tract spectrum and the first data associated with the speech rhythm;
a convertor configured to receive the first feature value vector including the first data associated with the speech rhythm extracted from the input speech signal to the speech rhythm conversion model and obtain the post-conversion speech rhythm; and
a speech synthesizer configured to use the post-conversion speech rhythm and the first data associated with the vocal tract spectrum extracted from the input speech signal to generate an output speech signal.
|