| CPC G10L 17/04 (2013.01) [G06N 7/01 (2023.01); G06N 20/00 (2019.01); G10L 17/02 (2013.01); G10L 17/24 (2013.01); G10L 25/18 (2013.01)] | 20 Claims |
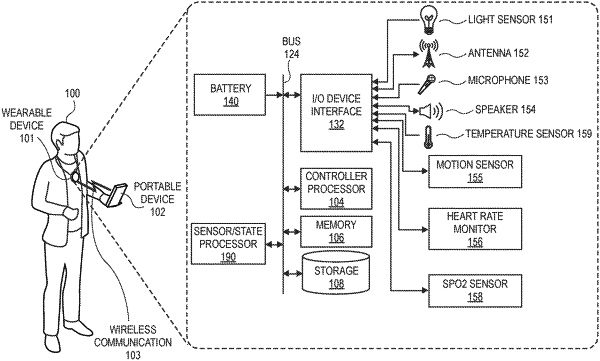
|
1. A computer-implemented method, comprising:
presenting, on a display of a portable device, a first phrase to be spoken as part of an enrollment process;
as the first phrase is presented on the portable device, recording, at the portable device, a first audio data collected by the portable device;
converting, at the portable device, at least a portion of the first audio data recorded by the portable device into a first log melspectrogram;
processing, at the portable device and with a machine learning model trained with log melspectrograms representative of a plurality of keywords, the first log melspectrogram to determine that at least a portion of the first log melspectrogram represents a first keyword of the plurality of keywords;
presenting, on the display of the portable device, a second phrase to be spoken as part of the enrollment process;
as the second phrase is presented on the portable device, recording, at the portable device, a second audio data collected by the portable device;
converting, at the portable device, at least a portion of the second audio data recorded by the portable device into a second log melspectrogram;
processing, at the portable device and with the machine learning model, the second log melspectrogram to determine that at least a portion of the second log melspectrogram represents a second keyword of the plurality of keywords;
in response to determining that the at least a portion of the first log melspectrogram represents the first keyword and determining that the at least a portion of the second log melspectrogram represents the second keyword, confirming that the first audio data and the second audio data correspond to phrases intentionally spoken as part of the enrollment process; and
in response to confirming that the first audio data and the second audio data correspond to phrases intentionally spoken:
sending, to a second device that is separate from the portable device, a request for a third audio data generated by the second device; and
generating an embedding vector representative of a speech, based at least in part on:
at least a first portion of the first audio data recorded by the portable device;
at least a second portion of the second audio data recorded by the portable device; and
at least a third portion of the third audio data received from the second device.
|