| CPC G10L 13/047 (2013.01) [G06N 3/045 (2023.01); G06N 3/08 (2013.01); G10L 13/0335 (2013.01); G10L 13/08 (2013.01); G10L 25/90 (2013.01)] | 20 Claims |
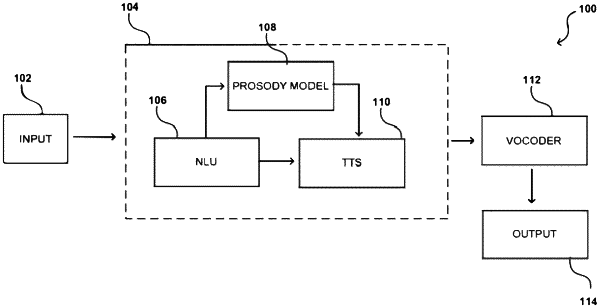
|
1. A computer-implemented method, comprising:
determining, from a plurality of audio samples including human speech, alignments between a phoneme and a phoneme duration;
generating, from the alignments, an alignment matrix corresponding to a distribution;
generating a set of synthesized training audio samples;
generating, from the set of synthesized training audio samples, synthesized distributions;
training one or more machine learning systems using, at least in part, the synthesized distributions and the distribution; and
removing, after training the one or more machine learning systems, the synthesized distributions to form an inferencing distribution.
|