| CPC G06T 7/11 (2017.01) [G06F 18/23 (2023.01); G06T 7/12 (2017.01); G06T 7/187 (2017.01); G06T 7/194 (2017.01); G06T 7/75 (2017.01); G06V 40/10 (2022.01); H04N 5/272 (2013.01); G06T 2207/10016 (2013.01); G06T 2207/30196 (2013.01)] | 14 Claims |
|
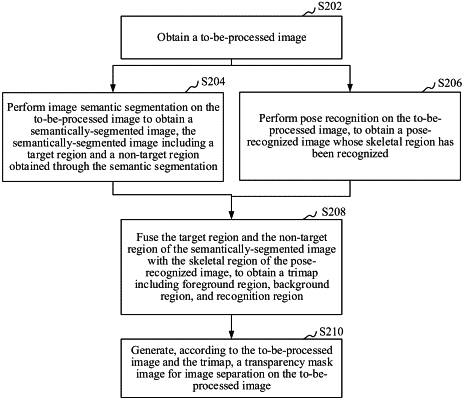
1. An image processing method, comprising:
obtaining a to-be-processed image;
performing image semantic segmentation on the to-be-processed image to obtain a semantically-segmented image, the semantically-segmented image comprising a target region and a non-target region obtained through the semantic segmentation;
inputting the to-be-processed image into a pose recognition model;
partitioning an image region in which the target in the to-be-processed image is located using a first hidden layer of the pose recognition model;
determining first skeletal key points corresponding to the target in the image region using a second hidden layer of the pose recognition model, the first hidden layer being located in front of the second hidden layer;
determining a plurality of skeletal key points in the to-be-processed image using the first hidden layer of the pose recognition model;
clustering the plurality of skeletal key points according to targets in the to-be-processed image using the second hidden layer of the pose recognition model, to obtain second skeletal key points corresponding to the target;
outputting, using the pose recognition model, a pose-recognized image recognizing skeletal region, the skeletal region being predicted according to the first skeletal key points and the second skeletal key points;
fusing the target region and the non-target region of the semantically-segmented image with the skeletal region of the pose-recognized image, to obtain a trimap comprising foreground region, background region, and recognition region; and
generating, according to the to-be-processed image and the trimap, a transparency mask image for image separation from the to-be-processed image.
|