| CPC G06Q 30/0633 (2013.01) [G06F 18/241 (2023.01); G06V 10/40 (2022.01); G06V 40/28 (2022.01)] | 20 Claims |
|
1. One or more computing devices, comprising:
one or more processors;
memory;
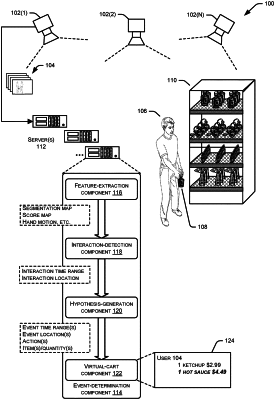
a feature-generation component, stored in the memory and executable on the one or more processors to:
receive image data from one or more cameras in an environment, the image data representing a user interacting with an item in the environment; and
generate, using the image data, feature data associated with at least one of the user or the item, the feature data comprising:
a segmentation map indicating at least a first location of a hand of the user;
a customer-interaction score map indicating that a second location of the image data represents an interaction between the hand of the user and the item; and
at least one of a direction or velocity of the hand of the user in the image data;
an interaction-detection component, stored in the memory and executable on the one or more processors to:
receive the feature data;
input the feature data into a first classifier that has been trained, using first training data, to determine whether the image data represents the interaction between the user and the item; and
generate, using the first classifier and based at least in part on inputting the feature data to the first classifier, first data indicating at least a first time-range of the interaction and a third location of the interaction;
a hypothesis-generation component, stored in the memory and executable on the one or more processors to:
receive the first data;
input the first data into a second classifier that has been trained, using second training data, to determine whether the interaction corresponds to at least one predefined activity of multiple predefined activities;
determine, using the second classifier and based at least in part on inputting the first data to the second classifier, that the image data represents a first predefined activity of the multiple predefined activities;
receive second data associated with a virtual cart of the user;
input the first data and the second data into a third classifier to determine a location of the first predefined activity, an action taken with respect to the item, and an identity of the item; and
generate, using the third classifier, third data indicating at least a second time-range of the first predefined activity, a fourth location of the first predefined activity, the action taken by the user with respect to the item, and the identity of the item; and
a virtual-cart component, stored in the memory and executable on the one or more processors to:
receive the third data; and
automatically update the virtual cart associated with the user in response to generating the third data to indicate the identity of the item and the action taken with respect to the item.
|