| CPC G06Q 30/01 (2013.01) [G06Q 30/0204 (2013.01); G06Q 30/0631 (2013.01)] | 18 Claims |
|
1. A system, comprising:
a computing instance including a server, a database, and a network storage, wherein the server includes a processor and a memory, wherein the database and the network storage is coupled to the server, wherein the processor is programmed to:
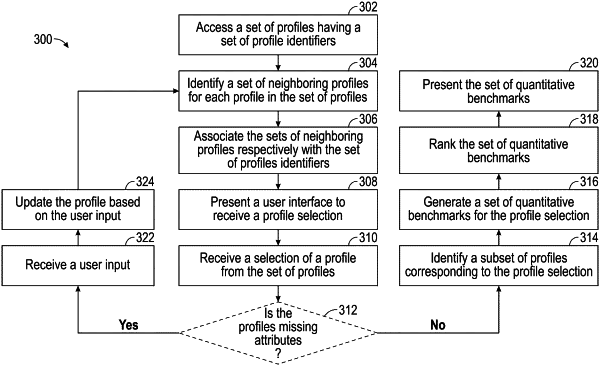
access a set of profiles, wherein each profile in the set of profiles contains a profile identifier and a set of attributes, wherein each set of attributes in the sets of attributes includes a numerical attribute, a categorical attribute, and a Boolean attribute;
identify a subset of profiles from the set of profiles for each respective profile in the set of profiles via a k-Nearest Neighbor (kNN) algorithm based on that subset of profiles being most similar to that respective profile according to a set of statistical distances measured and weighted using a statistical measure of entropy across the sets of attributes for the set of profiles based on the numerical attributes, the categorical attributes, and the Boolean attributes, wherein the kNN algorithm involves a kNN model that is unsupervised;
associate the subsets of profiles respectively with the set of profile identifiers;
present a user interface after the subsets of profiles are associated respectively with the set of profile identifiers, wherein the user interface is programmed to receive a user selection of a profile from the set of profiles;
receive the user selection from the user interface; and
in response to the user selection being received:
identify a profile identifier for the profile based on the user selection;
identify a subset of profiles associated with the profile identifier;
access a set of quantitative benchmarks related with a set of content using the sets of attributes for the subset of profiles where each quantitative benchmark in the set of quantitative benchmarks is (i) a numeric value that summarizes on a specific content in the set of content among the subset of profiles and (ii) organized in a parent-child structure with each parent benchmark having associated child benchmarks mapped according to suitability for the profile;
rank the set of quantitative benchmarks based on a degree of quantitative benchmark relevance among the subset of profiles associated with the profile identifier and a degree of profile deviation, wherein the degree of quantitative benchmark relevance measures how informative that respective quantitative benchmark is relative to other respective quantitative benchmarks for the profile, wherein the degree of profile deviation measures how different that respective quantitative benchmark is for the profile relative to those same respective quantitative benchmarks for the subset of profiles; and
present the set of quantitative benchmarks as ranked and organized in the parent-child structure in the user interface, wherein the computing instance includes an analytics environment and an API environment, wherein the analytics environment and the API environment are separate and distinct from each other, wherein the analytics environment includes a data engineering pipeline and an intermediate database, wherein the API environment includes an API server and a client logic, wherein the API server is in communication with the intermediate database and the client logic, wherein the data engineering pipeline identifies the subset of profiles from the set of profiles for each respective profile in the set of profiles based on that subset of profiles being most similar to that respective profile according to the set of statistical distances measured and weighted using the statistical measure of entropy across the sets of attributes for the set of profiles based on the numerical attributes, the categorical attributes, and the Boolean attributes and associates the subsets of profiles respectively with the set of profile identifiers in the intermediate database, wherein the API server presents the user interface on the client logic, accesses the set of quantitative benchmarks, and ranks the set of quantitative benchmarks.
|