| CPC G06N 3/08 (2013.01) [G06N 3/045 (2023.01)] | 20 Claims |
|
1. A method performed by one or more computers, the method comprising:
jointly training an action selection neural network and a state value neural network, wherein:
the action selection neural network is configured to process an observation of an environment, in accordance with current values of a set of action selection neural network parameters, to generate an output that defines a score distribution over a set of actions that can be performed by an agent to interact with the environment;
the state value neural network is configured to process an input comprising an observation of the environment to generate a state value for the observation that defines an estimate of a cumulative reward that will be received by the agent, starting from a state of the environment represented by the observation, by selecting actions using a current action selection policy defined by the current values of the set of action selection neural network parameters;
the training comprising:
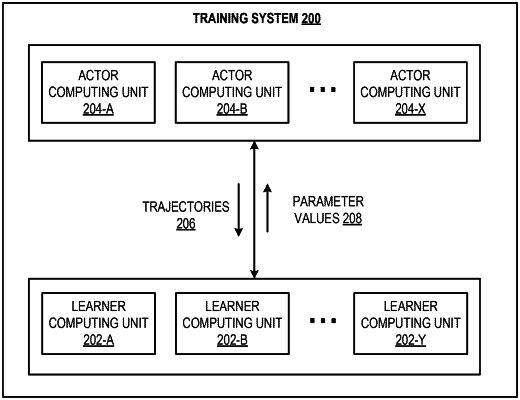
obtaining an off-policy trajectory that characterizes interaction of the agent with the environment over a sequence of time steps as the agent performed actions selected in accordance with an off-policy action selection policy that is different than the current action selection policy;
training the state value neural network on the off-policy trajectory, comprising:
determining a state value target that defines a prediction target for the state value neural network, wherein the state value target is a combination of:
(i) a state value for a first observation in the off-policy trajectory; and
(ii) a correction term that accounts for a discrepancy between the current action selection policy and the off-policy action selection policy;
training the state value neural network to reduce a discrepancy between the state value target and a state value generated by the state value neural network by processing the first observation in the off-policy trajectory; and
training the action selection neural network on the off-policy trajectory using the state value neural network.
|