| CPC G06N 3/08 (2013.01) [G06N 3/045 (2023.01); G06N 3/047 (2023.01)] | 20 Claims |
|
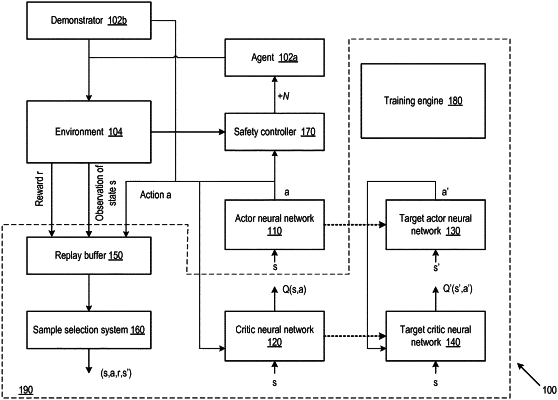
1. A reinforcement learning system for selecting actions to be performed by an agent interacting with an environment to perform a task, the system comprising one or more computers and one or more storage devices storing instructions that when executed by the one or more computers, cause the one or more processors to perform operations comprising:
receiving an observation comprising state data characterizing a state of the environment, and reward data representing a reward from operating with an action in the environment;
implementing at least one actor neural network, coupled to receive the state data and configured to define a policy function mapping the state data to action data defining an action, wherein the at least one actor neural network has an output to provide the action data for the agent to perform the action, and wherein the environment transitions to a new state in response to the action;
implementing at least one critic neural network, coupled to receive the action data, the state data, and return data derived from the reward data, and configured to define a value function which generates an error signal;
storing reinforcement learning transitions in a replay buffer, the reinforcement learning transitions comprising operation transition data from operation of the system, wherein the operation transition data comprises tuples of said state data, said action data, said reward data and new state data representing said new state; and
receiving training data defining demonstration transition data, the demonstration transition data comprising a set of said tuples from a demonstration of the task within the environment, wherein reinforcement learning transitions stored in the replay buffer further comprise the demonstration transition data; and
training the at least one actor neural network and the at least one critic neural network off-policy using the error signal and using stored tuples from the replay buffer comprising tuples from both the operation transition data and the demonstration transition data.
|