| CPC G06N 20/00 (2019.01) [G06F 11/3048 (2013.01); G06F 16/35 (2019.01); G06N 3/04 (2013.01); G06N 7/01 (2023.01); G05B 23/0281 (2013.01); G06F 16/285 (2019.01); G06F 16/45 (2019.01); G06F 16/55 (2019.01); G06F 16/65 (2019.01); G06F 16/75 (2019.01); G06F 16/906 (2019.01); G06F 18/2137 (2023.01); G06F 18/23 (2023.01); G06N 5/025 (2013.01); G16H 50/20 (2018.01); G16H 50/50 (2018.01)] | 17 Claims |
|
1. A non-transitory computer-readable medium including executable instructions, the instructions being executable by a processor to perform a method, the method comprising:
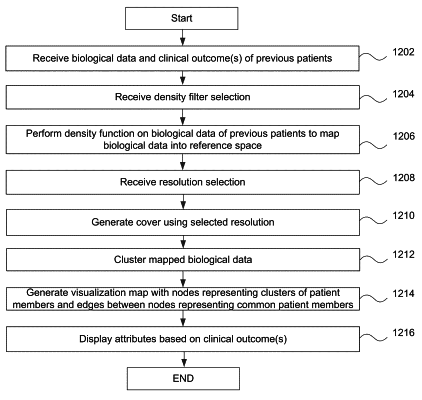
receiving a network of a plurality of nodes and a plurality of edges, each of the nodes of the plurality of nodes comprising members representative of at least one subset of initial data points, each of the edges of the plurality of edges connecting nodes that share at least one data point of the initial data points, each node of the plurality of nodes being defined by a mapping of the initial data points to a reference space using a distance metric and a location of the initial data points within a set of overlapping open sets within the reference space, each node of the plurality of nodes including at least a subset of the initial data points within one open set of the set of overlapping open sets, distance between two or more of the initial data points being based at least in part on distance between values of feature sets of the two or more of the initial data points, a data point of the initial data points including biological data of a first person, the biological data of the first person representing conditions of the first person;
generating a training data set using the network of the plurality of nodes and the plurality of edges, the training data set including at least a subset of the initial data points that are members of a subset of nodes of the plurality of nodes and at least one feature of a plurality of features of the initial data points based on at least one edge of the plurality of edges between at least two nodes of the plurality of nodes, the training data set including rows and columns, each row defining a data point of the training data set and each column defining at least one of the plurality of features, the training data set including an initial number of columns, each column including values associated with a feature of a plurality of features, the plurality of features representing biological data of persons;
grouping the data points of the training data set into a plurality of groups, each group including data points of the training data set that are members of a set of interconnected nodes of the subset of nodes of the plurality of nodes, each group of the plurality of groups including a different subset of data points of the training data set, each data point of the training data set being a member of at least one group of the plurality of groups, each group of the plurality of groups including the initial data points that are members of a subset of the plurality of nodes;
creating a first transformation data set, the first transformation data set including the training data set as well as a plurality of feature subsets, each of the plurality of feature subsets being associated with at least one group of the plurality of groups, values of a particular data point for a particular feature subset for a particular group being based on values of the particular data point in the training data set if the particular data point is a member of the particular group;
applying a machine learning model to the first transformation data set to generate a prediction model;
receiving an analysis data set, the analysis data set including at least one row and the columns, the at least one row defining at least one data point including biological data of a second person;
grouping the at least one data point of the analysis data set into one or more groups of the plurality of groups;
creating a second transformation data set, the second transformation data set including the analysis data set as well as the plurality of feature subsets, each of the plurality of feature subsets being associated with the at least one group of the plurality of groups, values of a particular data point of the analysis data set for a particular feature subset for a particular group being based on values of the particular data point in the analysis data set if the particular data point is a member of the particular group;
applying the prediction model to the second transformation data set to generate predicted outcomes, the predicted outcomes related to clinical outcomes of the second person; and
generating a report indicating one or more of the predicted outcomes related to clinical outcomes of the second person.
|