| CPC G06F 8/77 (2013.01) [G06F 8/427 (2013.01); G06F 8/75 (2013.01); G06F 18/2148 (2023.01); G06F 18/2185 (2023.01); G06N 20/00 (2019.01)] | 18 Claims |
|
1. A method for facilitating identification of secrets in source code by using machine learning, the method being implemented by at least one processor, the method comprising:
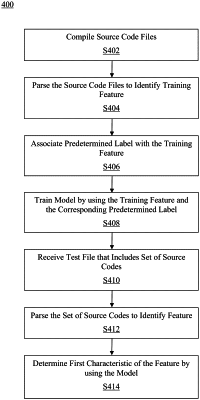
retrieving, by the at least one processor, a plurality of files from at least one repository, each of the plurality of files including a source code file;
parsing, by the at least one processor, the source code file to identify at least one training feature;
associating, by the at least one processor, a predetermined label with each of the at least one training feature, the predetermined label corresponding to at least one from among a secret label and a non-secret label;
training, by the at least one processor, at least one model by using the at least one training feature and the corresponding predetermined label;
receiving, by the at least one processor via a graphical user interface, at least one test file, the at least one test file including at least one set of source codes;
parsing, by the at least one processor, the at least one set of source codes to identify at least one feature;
determining, by the at least one processor using the at least one model, at least one first characteristic of the at least one feature;
determining, by the at least one processor using the at least one model, at least one second characteristic based on a first attribute of the at least one first characteristic, the at least one second characteristic including at least one from among an obsolete characteristic, a usable characteristic, and a deprecated characteristic; and
determining, by the at least one processor using the at least one model, at least one third characteristic based on a second attribute of the at least one second characteristic, the at least one third characteristic including at least one from among a production characteristic and a development characteristic.
|