| CPC G06F 40/30 (2020.01) [G06F 40/205 (2020.01); G06F 40/279 (2020.01)] | 19 Claims |
|
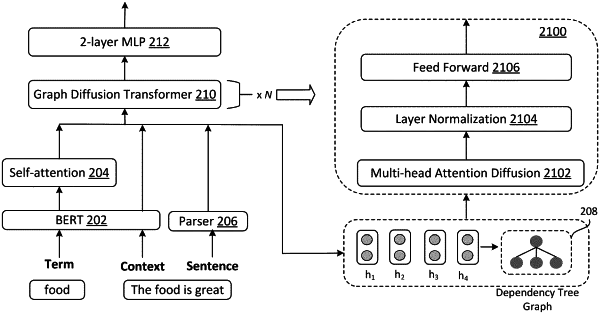
1. A system comprising a computing device, the computing device comprising a processor and a storage device storing computer executable code, wherein the computer executable code comprises a plurality of graph diffusion transformer (GDT) layers, and wherein the computer executable code, when executed at the processor, is configured to:
receive a sentence having an aspect term and context, the aspect term having a classification label;
convert the sentence into a dependency tree graph;
calculate, by using an l-th GDT layer of the plurality of GDT layers, an attention matrix of the dependency tree graph based on one-hop attention between any two of a plurality of nodes in the dependency tree graph;
calculate graph attention diffusion from multi-hop attention between any two of the plurality of nodes in the dependency tree graph based on the attention matrix;
obtain an embedding of the dependency tree graph using the graph diffusion attention;
classify the aspect term based on the embedding of the dependency tree graph to obtain predicted classification of the aspect term;
calculate a loss function based on the predicted classification of the aspect term and the classification label of the aspect term; and
adjust parameters of models in the computer executable code based on the loss function,
wherein the l-th GDT layer of the plurality of GDT layers is configured to calculate the attention matrix by:
calculating an attention score si,j(l)=σ2 (v*σ1(Whhi(l)∥Wthj(l))) for nodes i and node j in the dependency tree graph, wherein Wh, Wt∈
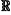 d×d and v∈2×d are learnable weights, hi(l) is a feature of node i at the l-th GDT layer, d is a hidden dimension of hi(l), ∥ is a concatenation operation, σ1 is a ReLU activation function, and σ2 is a LeakyReLU activation function; d×d and v∈2×d are learnable weights, hi(l) is a feature of node i at the l-th GDT layer, d is a hidden dimension of hi(l), ∥ is a concatenation operation, σ1 is a ReLU activation function, and σ2 is a LeakyReLU activation function;obtaining attention score matrix S(l) by:
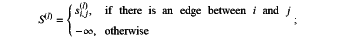 and
calculating the attention matrix A(l) by: A(l)=softmax(S(l)).
|