| CPC G06F 40/30 (2020.01) [G06F 3/0484 (2013.01)] | 18 Claims |
|
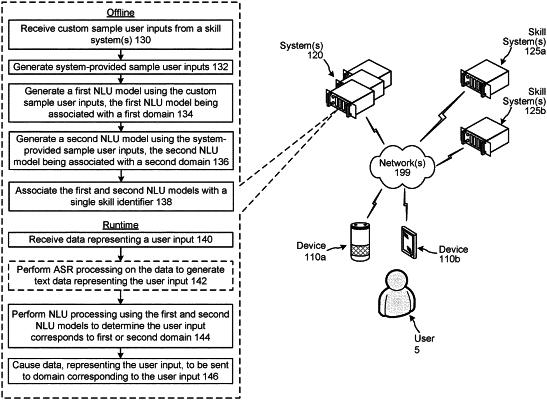
1. A system for processing natural language inputs, the system comprising:
a first skill component configured to process with respect to a first domain and a second domain, wherein the first skill component is unable to process with respect to a third domain;
a second skill component configured to process with respect to the third domain;
at least one processor; and
at least one memory comprising instructions that, when executed by the at least one processor, cause the system to:
receive first audio data representing a first spoken user input;
determine first automatic speech recognition (ASR) output data corresponding to the first audio data;
determine, using the first ASR output data, a first natural language understanding (NLU) hypothesis corresponding to the first spoken user input, the first NLU hypothesis including a first intent indicator corresponding to the first domain;
based at least in part on the first intent indicator corresponding to the first domain, send the first NLU hypothesis to the first skill component instead of the second skill component, wherein the first skill component is configured to process the first NLU hypothesis to generate first output data responsive to the first spoken user input;
after sending the first NLU hypothesis, receive the first output data from the first skill component;
present the first output data;
receive second audio data representing a second spoken user input;
determine second ASR output data corresponding to the second audio data;
determine, using the second ASR output data, a second NLU hypothesis corresponding to the second spoken user input, the second NLU hypothesis including a second intent indicator corresponding to the second domain;
based at least in part on the second intent indicator corresponding to the second domain, send the second NLU hypothesis to the first skill component instead of the second skill component, wherein the first skill component is configured to process the second NLU hypothesis to generate second output data responsive to the second spoken user input;
after sending the second NLU hypothesis, receive the second output data from the first skill component; and
present the second output data.
|