| CPC G06F 40/295 (2020.01) [G06F 40/205 (2020.01); G06F 40/279 (2020.01); G06F 40/35 (2020.01); G06F 40/40 (2020.01); G06V 30/19147 (2022.01)] | 20 Claims |
|
1. A method, comprising:
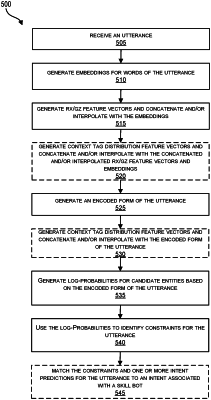
receiving, at a chatbot system comprising a processor, at least one utterance comprising one or more words;
generating, by a transformer-based model of the chatbot system, a plurality of embeddings for the one or more words of the at least one utterance;
generating, by a first vectorizer of the chatbot system, at least one regular expression and gazetteer feature vector for the at least one utterance;
generating, by a second vectorizer of the chatbot system, at least one context tag distribution feature vector for the at least one utterance;
concatenating or interpolating the plurality of embeddings with the at least one regular expression and gazetteer feature vector and the at least one context tag distribution feature vector to generate a first set of feature vectors;
generating, by a main sequence model of the chatbot system, an encoded form of the at least one utterance based on the first set of feature vectors;
generating, by a discriminative model of the chatbot system, a plurality of log-probabilities for candidate entities based on the encoded form of the at least one utterance; and
identifying, using the plurality of log-probabilities, one or more constraints for the at least one utterance based on the candidate entities.
|