| CPC G06F 16/3329 (2019.01) [G06F 40/20 (2020.01); G06F 40/284 (2020.01); G06F 40/35 (2020.01); G06N 3/08 (2013.01)] | 22 Claims |
|
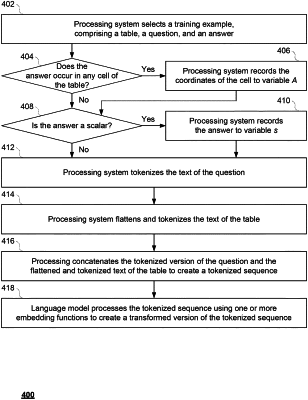
1. A computer-implemented method of training a language model, comprising:
pre-training the language model, using one or more processors of a processing system, based on a plurality of pre-training examples comprising a plurality of counterfactual examples each comprising a respective table, a respective first statement, and a respective second statement; and
fine-tuning the language model, using the one or more processors, based on a plurality of fine-tuning examples each comprising a respective question, a respective answer, and a corresponding table;
wherein, for a first fine-tuning example of the plurality of fine-tuning examples having the respective answer being a scalar, the fine-tuning comprises:
generating an estimated answer to the respective question based on:
the corresponding table;
the language model's predictions of whether the respective answer is based on each cell of a plurality of cells of the corresponding table; and
the language model's predictions of whether the respective answer is based on each aggregation operation of a plurality of aggregation operations;
generating a first loss value based on the estimated answer;
generating a second loss value based on the language model's predictions of whether the respective answer is based on each aggregation operation of the plurality of aggregation operations; and
modifying one or more parameters of the language model based at least on the first and second loss values.
|